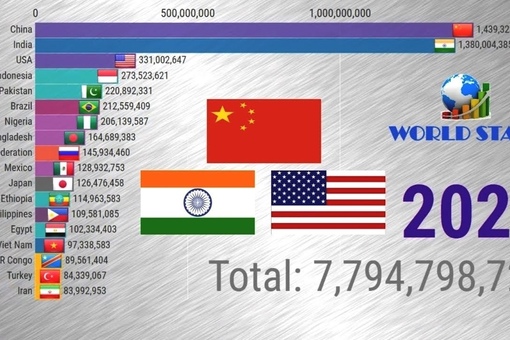
Список стран по населению | МЕРКАТОР
| № | Страна | Население_(чел.) | Дата информации |
|---|---|---|---|
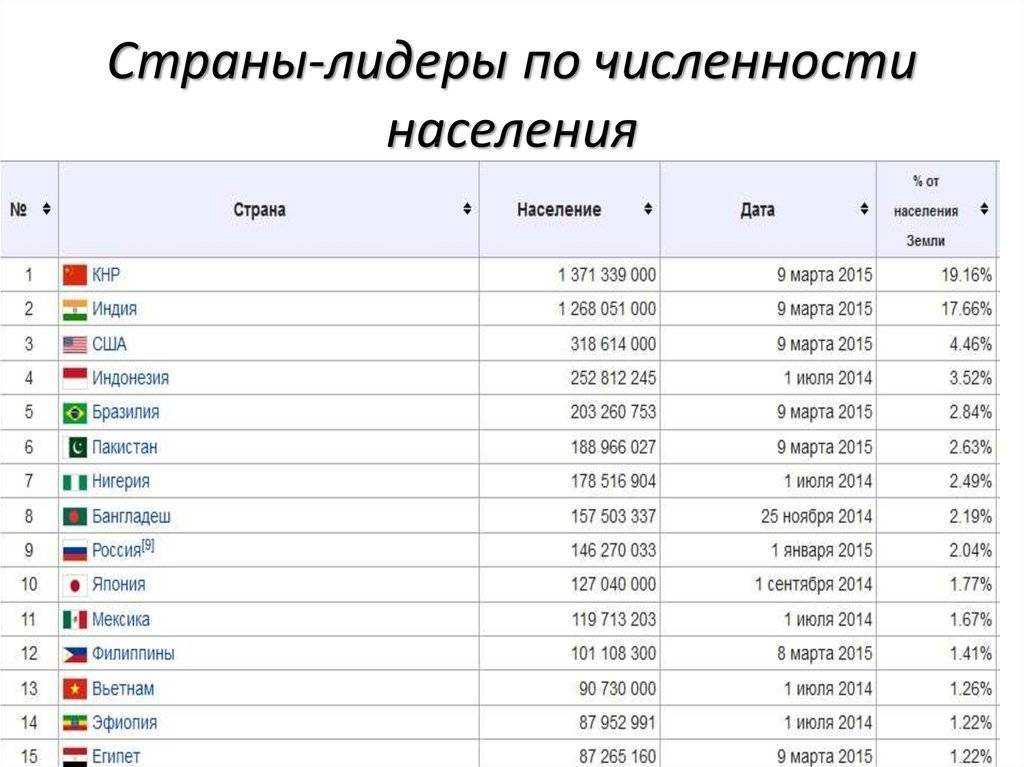
| 1 | Китай (без Тайваня) | 1 397 897 720 | июль 2021 |
| 2 | Индия | 1 339 330 514 | июль 2021 |
| 3 | Соединенные Штаты Америки | 334 998 398 | июль 2021 |
| 4 | Индонезия | 275 122 131 | июль 2021 |
| 5 | Пакистан | 238 181 034 | июль 2021 |
| 6 | Нигерия | 219 463 862 | июль 2021 |
| 7 | Бразилия | 213 445 417 | июль 2021 |
| 8 | Бангладеш | 164 098 818 | июль 2021 |
| 9 | Россия | 140 792 347 | июль 2021 |
| 10 | Мексика | 130 207 371 | июль 2021 |
| 11 | Япония | 124 704 912 | июль 2021 |
| 12 | Эфиопия | 110 871 031 | июль 2021 |
| 13 | Филиппины | 110 818 325 | июль 2021 |
| 14 | Египет | 106 437 241 | июль 2021 |
| 15 | Демократическая Республика Конго | 105 044 646 | июль 2021 |
| 16 | Вьетнам | 102 789 598 | июль 2021 |
| 17 | Иран | 85 888 910 | июль 2021 |
| 18 | Турция | 82 482 383 | июль 2021 |
| 19 | Германия | 79 903 481 | июль 2021 |
| 20 | Таиланд | 69 480 520 | июль 2021 |
| 21 | Франция | 68 084 217 | июль 2021 |
| 22 | Великобритания | 67 081 000 | июнь 2020 |
| 23 | Италия | 62 390 364 | июль 2021 |
| 24 | Танзания | 62 092 761 | июль 2021 |
| 25 | Мьянма | 57 069 099 | июль 2021 |
| 26 | Южно-Африканская Республика | 56 978 635 | июль 2021 |
| 27 | Кения | 54 685 051 | июль 2021 |
| 28 | Южная Корея | 51 715 162 | июль 2021 |
| 29 | Колумбия | 50 355 650 | июль 2021 |
| 30 | Испания | 47 260 584 | июль 2021 |
| 31 | Судан | 46 751 152 | июль 2021 |
| 32 | Аргентина | 45 864 941 | июль 2021 |
| 33 | Уганда | 44 712 143 | июль 2021 |
| 34 | Украина | 43 745 640 | июль 2021 |
| 35 | Алжир | 43 576 691 | июль 2021 |
| 36 | Ирак | 39 650 145 | июль 2021 |
| 37 | Польша | 38 185 913 | июль 2021 |
| 38 | Канада | 37 943 231 | июль 2021 |
| 39 | Афганистан | 37 466 414 | июль 2021 |
| 40 | Марокко | 36 561 813 | июль 2021 |
| 41 | Саудовская Аравия | 34 783 757 | июль 2021 |
| 42 | Ангола | 33 642 646 | июль 2021 |
| 43 | Малайзия | 33 519 406 | июль 2021 |
| 44 | Гана | 32 372 889 | июль 2021 |
| 45 | Перу | 32 201 224 | июль 2021 |
| 46 | Мозамбик | 30 888 034 | июль 2021 |
| 47 | Узбекистан | 30 842 796 | июль 2021 |
| 48 | Непал | 30 424 878 | июль 2021 |
| 49 | Йемен | 30 399 243 | июль 2021 |
| 50 | Венесуэла | 29 069 153 | июль 2021 |
| 51 | Камерун | 28 524 175 | июль 2021 |
| 52 | Кот-д’Ивуар | 28 088 455 | июль 2021 |
| 53 | Мадагаскар | 27 534 354 | июль 2021 |
| 54 | Северная Корея | 25 831 360 | июль 2021 |
| 55 | Австралия | 25 809 973 | июль 2021 |
| 56 | Нигер | 23 605 767 | июль 2021 |
| 57 | Тайвань[1] | 23 572 052 | июль 2021 |
| 58 | Шри-Ланка | 23 044 123 | июль 2021 |
| 59 | Буркина-Фасо | 21 382 659 | июль 2021 |
| 60 | Румыния | 21 230 362 | июль 2021 |
| 61 | Сирия | 20 384 316 | июль 2021 |
| 62 | Малави | 20 308 502 | июль 2021 |
| 63 | Мали | 20 137 527 | июль 2021 |
| 64 | Казахстан | 19 245 793 | июль 2021 |
| 65 | Замбия | 19 077 816 | июль 2021 |
| 66 | Чили | 18 307 925 | июль 2021 |
| 67 | Гватемала | 17 422 821 | июль 2021 |
| 68 | Чад | 17 414 108 | июль 2021 |
| 69 | Нидерланды | 17 337 403 | июль 2021 |
| 70 | Камбоджа | 17 304 363 | июль 2021 |
| 71 | Эквадор | 17 093 159 | июль 2021 |
| 72 | Сенегал | 16 082 442 | июль 2021 |
| 73 | Зимбабве | 14 829 988 | июль 2021 |
| 74 | Бенин | 13 301 694 | июль 2021 |
| 75 | Руанда | 12 943 132 | июль 2021 |
| 76 | Гвинея | 12 877 894 | июль 2021 |
| 77 | Бурунди | 12 241 065 | июль 2021 |
| 78 | Сомали | 12 094 640 | июль 2021 |
| 79 | Тунис | 11 811 335 | июль 2021 |
| 80 | Бельгия | 11 778 842 | июль 2021 |
| 81 | Боливия | 11 758 869 | июль 2021 |
| 82 | Гаити | 11 198 240 | июль 2021 |
| 83 | Куба | 11 032 343 | июль 2021 |
| 84 | Южный Судан | 10 984 074 | июль 2021 |
| 85 | Иордания | 10 909 567 | июль 2021 |
| 86 | Чехия | 10 702 596 | июль 2021 |
| 87 | Доминиканская Республика | 10 597 348 | июль 2021 |
| 88 | Греция | 10 569 703 | июль 2021 |
| 89 | Азербайджан | 10 282 283 | июль 2021 |
| 90 | Португалия | 10 263 850 | июль 2021 |
| 91 | Швеция | 10 261 767 | июль 2021 |
| 92 | Объединенные Арабские Эмираты | 9 856 612 | июль 2021 |
| 93 | Венгрия | 9 728 337 | июль 2021 |
| 94 | Беларусь | 9 441 842 | июль 2021 |
| 95 | Гондурас | 9 346 277 | июль 2021 |
| 96 | Таджикистан | 8 990 874 | июль 2021 |
| 97 | Австрия | 8 884 864 | июль 2021 |
| 98 | Израиль | 8 787 045 | июль 2021 |
| 99 | Швейцария | 8 453 550 | июль 2021 |
| 100 | Того | 8 283 189 | июль 2021 |
| 101 | Лаос | 7 574 356 | июль 2021 |
| 102 | Папуа — Новая Гвинея | 7 399 757 | июль 2021 |
| 103 | Парагвай | 7 272 639 | июль 2021 |
| 104 | Гонконг (Китай) | 7 263 234 | июль 2021 |
| 105 | Ливия | 7 017 224 | июль 2021 |
| 106 | Сербия (без Косово) | 6 974 289 | июль 2021 |
| 107 | Болгария | 6 919 180 | июль 2021 |
| 108 | Сьерра-Леоне | 6 807 277 | июль 2021 |
| 109 | Сальвадор | 6 528 135 | июль 2021 |
| 110 | Никарагуа | 6 243 931 | июль 2021 |
| 111 | Эритрея | 6 147 398 | июль 2021 |
| 112 | Киргизия | 6 018 789 | июль 2021 |
| 113 | Дания | 5 894 687 | июль 2021 |
| 114 | Сингапур | 5 866 139 | июль 2021 |
| 115 | Туркменистан | 5 579 889 | июль 2021 |
| 116 | Финляндия | 5 557 098 | июль 2021 |
| 117 | Норвегия | 5 509 609 | июль 2021 |
| 118 | Словакия | 5 436 066 | июль 2021 |
| 119 | Республика Конго | 5 417 414 | июль 2021 |
| 120 | Центральноафриканская Республика | 5 357 984 | июль 2021 |
| 121 | Ливан | 5 261 372 | июль 2021 |
| 122 | Ирландия | 5 224 884 | июль 2021 |
| 123 | Либерия | 5 214 030 | июль 2021 |
| 124 | Коста-Рика | 5 151 140 | июль 2021 |
| 125 | Новая Зеландия | 4 991 442 | июль 2021 |
| 126 | Грузия | 4 933 674 | июль 2021 |
| 127 | Палестина | 4 906 308 | июль 2021 |
| 128 | Хорватия | 4 208 973 | июль 2021 |
| 129 | Мавритания | 4 079 284 | июль 2021 |
| 130 | Панама | 3 928 646 | июль 2021 |
| 131 | Босния и Герцеговина | 3 824 782 | июль 2021 |
| 132 | Оман | 3 694 755 | июль 2021 |
| 133 | Уругвай | 3 398 239 | июль 2021 |
| 134 | Молдова | 3 323 875 | июль 2021 |
| 135 | Монголия | 3 198 913 | июль 2021 |
| 136 | Пуэрто-Рико (США) | 3 142 779 | июль 2021 |
| 137 | Албания | 3 088 385 | июль 2021 |
| 138 | Кувейт | 3 032 065 | июль 2021 |
| 139 | Армения | 3 011 609 | июль 2021 |
| 140 | Ямайка | 2 816 602 | июль 2021 |
| 141 | Литва | 2 711 566 | июль 2021 |
| 142 | Намибия | 2 678 191 | июль 2021 |
| 143 | Катар | 2 479 995 | июль 2021 |
| 144 | Ботсвана | 2 350 667 | июль 2021 |
| 145 | Габон | 2 284 912 | июль 2021 |
| 146 | Гамбия | 2 221 301 | июль 2021 |
| 147 | Лесото | 2 177 740 | июль 2021 |
| 148 | Северная Македония | 2 128 262 | июль 2021 |
| 149 | Словения | 2 102 106 | июль 2021 |
| 150 | Гвинея-Бисау | 1 976 187 | июль 2021 |
| 151 | Косово[2] | 1 935 259 | июль 2021 |
| 152 | Латвия | 1 862 687 | июль 2021 |
| 153 | Бахрейн | 1 526 929 | июль 2021 |
| 154 | Чечня | 1 510 824 | июль 2021 |
| 155 | Восточный Тимор | 1 413 958 | июль 2021 |
| 156 | Маврикий | 1 386 129 | июль 2021 |
| 157 | Кипр | 1 281 506 | июль 2021 |
| 158 | Тринидад и Тобаго | 1 221 047 | июль 2021 |
| 159 | Эстония | 1 220 042 | июль 2021 |
| 160 | Эсватини | 1 113 276 | июль 2021 |
| 161 | Фиджи | 939 535 | июль 2021 |
| 162 | Джибути | 938 413 | июль 2021 |
| 163 | Коморские Острова | 864 335 | июль 2021 |
| 164 | Бутан | 857 423 | июль 2021 |
| 165 | Экваториальная Гвинея | 857 008 | июль 2021 |
| 166 | Гайана | 787 971 | июль 2021 |
| 167 | Соломоновы Острова | 690 598 | июль 2021 |
| 168 | Люксембург | 639 589 | июль 2021 |
| 169 | Макао (Китай) | 630 396 | июль 2021 |
| 170 | Суринам | 614 749 | июль 2021 |
| 171 | Черногория | 607 414 | июль 2021 |
| 172 | Кабо-Верде | 589 451 | июль 2021 |
| 173 | Западная Сахара[3] | 565 581 | июль 2021 |
| 174 | Бруней | 471 103 | июль 2021 |
| 175 | Мальта | 460 891 | июль 2021 |
| 176 | Белиз | 405 633 | июль 2021 |
| 177 | Мальдивы | 390 669 | июль 2021 |
| 178 | Исландия | 354 234 | июль 2021 |
| 179 | Багамские Острова | 352 655 | июль 2021 |
| 180 | Вануату | 303 009 | июль 2021 |
| 181 | Барбадос | 301 865 | июль 2021 |
| 182 | Французская Полинезия (Франция) | 297 154 | июль 2021 |
| 183 | Новая Каледония (Франция) | 293 608 | июль 2021 |
| 184 | Сан-Томе и Принсипи | 213 948 | июль 2021 |
| 185 | Самоа | 204 898 | июль 2021 |
| 186 | Гуам (США) | 168 801 | июль 2021 |
| 187 | Сент-Люсия | 166 637 | июль 2021 |
| 188 | Кюрасао (Нидерланды) | 151 885 | июль 2021 |
| 189 | Аруба (Нидерланды) | 120 917 | июль 2021 |
| 190 | Гренада | 113 570 | июль 2021 |
| 191 | Кирибати | 113 001 | июль 2021 |
| 192 | Американские Виргинские Острова (США) | 105 870 | июль 2021 |
| 193 | Тонга | 105 780 | июль 2021 |
| 194 | Федеративные Штаты Микронезии | 101 675 | июль 2021 |
| 195 | Джерси (Великобритания) | 101 476 | июль 2021 |
| 196 | Сент-Винсент и Гренадины | 101 145 | июль 2021 |
| 197 | Антигуа и Барбуда | 99 175 | июль 2021 |
| 198 | Сейшельские Острова | 96 387 | июль 2021 |
| 199 | Остров Мэн (Великобритания) | 90 895 | июль 2021 |
| 200 | Андорра | 85 645 | июль 2021 |
| 201 | Маршалловы Острова | 78 831 | июль 2021 |
| 202 | Доминика | 74 584 | июль 2021 |
| 203 | Бермудские Острова (Великобритания) | 72 084 | июль 2021 |
| 204 | Гернси (Великобритания) | 67 334 | июль 2021 |
| 205 | Каймановы Острова (Великобритания) | 63 131 | июль 2021 |
| 206 | Гренландия (Дания) | 57 799 | июль 2021 |
| 207 | Острова Теркс и Кайкос (Великобритания) | 57 196 | июль 2021 |
| 208 | Сент-Китс и Невис | 54 149 | июль 2021 |
| 209 | Фарерские Острова (Дания) | 51 943 | июль 2021 |
| 210 | Северные Марианские Острова (США) | 51 659 | июль 2021 |
| 211 | Американское Самоа (США) | 46 366 | июль 2021 |
| 212 | Синт-Мартен (Нидерланды) | 44 564 | июль 2021 |
| 213 | Лихтенштейн | 39 425 | июль 2021 |
| 214 | Британские Виргинские Острова (Великобритания) | 37 891 | июль 2021 |
| 215 | Сан-Марино | 34 467 | июль 2021 |
| 216 | Сен-Мартен (Франция) | 32 680 | июль 2021 |
| 217 | Монако | 31 223 | июль 2021 |
| 218 | Аландские Острова (Финляндия) | 30 344 | июль 2021 |
| 219 | Гибралтар (Великобритания) | 29 516 | июль 2021 |
| 220 | Палау | 21 613 | июль 2021 |
| 221 | Ангилья (Великобритания) | 18 403 | июль 2021 |
| 222 | Акротири и Декелия (Великобритания) | 18 195 | 2020 |
| 223 | Уоллис и Футуна (Франция) | 15 851 | июль 2021 |
| 224 | Тувалу | 11 448 | июль 2021 |
| 225 | Науру | 9 770 | июль 2021 |
| 226 | Острова Кука (Новая Зеландия) | 8 327 | июль 2021 |
| 227 | Острова Святой Елены, Вознесения и Тристан-да-Кунья (Великобритания) | 7 915 | июль 2021 |
| 228 | Сен-Бартелеми (Франция) | 7 116 | июль 2021 |
| 229 | Монтсеррат (Великобритания) | 5 387 | июль 2021 |
| 230 | Сен-Пьер и Микелон (Франция) | 5 321 | июль 2021 |
| 231 | Фолклендские Острова (Великобритания) | 3 198 | 2016 |
| 232 | Британская Территория в Индийском Океане (Великобритания) | 3 000 | 2018 |
| 233 | Свальбард (Норвегия) | 2 926 | янв. 2021 2021 |
| 234 | Остров Рождества (Австралия) | 2 205 | 2016 |
| 235 | Ниуэ (Новая Зеландия) | 2 000 | июль 2021 |
| 236 | Остров Норфолк (Австралия) | 1 748 | 2016 |
| 237 | Токелау (Новая Зеландия) | 1 647 | 2019 |
| 238 | Ватикан | 1 000 | 2019 |
| 239 | Кокосовые Острова (Австралия) | 596 | июль 2014 |
| 240 | Острова Питкэрн (Великобритания) | 50 | 2021 |
Примечания:
- Тайвань – частично признанное государство. Украиной не признано.
- Косово – частично признанное государство. Украиной не признано.
- Западная Сахара – признана ООН. Оккупирована Марокко.
Источник:
- Population – https://www.cia.gov/the-world-factbook/field/population/country-comparison
Помогите решить задачку по sql
Вопрос задан
Изменён
1 год 8 месяцев назад
Просмотрен
11k раз
В реляционной базе данных существуют таблицы:
Cities — список городов
id — первичный ключ
name — название
population — численность населения
founded — год основания
country_id — id страны
Countries — список стран
id — первичный ключ
name — название
population — численность населения
gdp — валовый продукт в долларах
Companies — компании
id — первичный ключ
name — название
city_id — город в котором находится штаб-квартира
revenue — годовая выручка в долларах
labors — численность сотрудников
Составьте запрос, который:
Для всех стран в базе данных посчитать количество компаний со штаб квартирами в этой стране численность сотрудников в которых больше 1000 человек
В результате должны быть только количество компаний и названия стран с населением более 1 миллиона человек и валовым продуктом более 10 миллиардов долларов, у которых суммарная выручка выбранных компаний составляет более 1 миллиарда долларов
Мой вариант:
select *, count(labors),count(revenue),FROM Companies group by name HAVING count(labors) >=1000 AND count(revenue) >= 1000000000
( это я пытался выстроить компании с численность сотрудников > 1000 и доходом более 1ккк)
Далее я так полагаю нужно получившийся список сравнить со списком (Countries ) и составить новый список и новый список сравнить со с писком (Cities ) и этот список будет ответом.
П.С. Хотелось бы получить не просто ответ но и логику выполнения такого задания.
4
Это учебное задание и вы должны решить его сами. Но вы даже не попытались.
Вот прямо сходу:
select *— вам указан конкретный список полей для вывода, никаких звёздочек, конкретные поля в конкретном порядкеДля всех стран— а у вас таблица со странами даже не участвует в запросе, хотя по формулировке очевидно, что всё будет завязано на список стран,FROM— это что? Этот запрос даже не скомпилируется
Вам нужно более тщательно прочитать задание и попытаться хотя бы в первом приближении без изысков написать запрос «в лоб». А дальше уже разбираться — что вы не знаете как сделать, пробовать разные варианты, и если не получится что-то — задавать более конкретный вопрос.
То есть нужно написать SELECT конкретных полей (и аггрегаций) из конкретного перечня таблиц, связать их как-то через условия, эти таблицы, ну и дальше над этим всем работать.
1
Один из вариантов реализации:
SELECT cou.name AS `Country`, COUNT(com.id)
FROM Companies com
LEFT JOIN Cities cit
ON cit.id = com.city_id
LEFT JOIN Countries cou
ON cit.country_id = cou.id
WHERE com.labors > 1000
AND city_id IN (SELECT cit2.id
FROM Cities cit2
LEFT JOIN Countries cou2
ON cit2.country_id = cou2.id
WHERE cou2.population > 1000000 AND cou2.gdp > 10000000000)
GROUP BY cou.id
HAVING SUM(com.revenue) > 1000000000
Источник: https://skalolaskovy.ru/sql/572-yandeex-sql-task
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
By clicking “Отправить ответ”, you agree to our terms of service and acknowledge that you have read and understand our privacy policy and code of conduct.
Вопрос достоинства. Влияние быстрого роста населения на развивающиеся страны
Сохранить цитату в файл
Формат:
Резюме (текст)PubMedPMIDAbstract (текст)CSV
Добавить в коллекции
- Создать новую коллекцию
- Добавить в существующую коллекцию
Назовите свою коллекцию:
Имя должно содержать менее 100 символов
Выберите коллекцию:
Не удалось загрузить вашу коллекцию из-за ошибки
Повторите попытку
Добавить в мою библиографию
- Моя библиография
Не удалось загрузить делегатов из-за ошибки
Повторите попытку
Ваш сохраненный поиск
Название сохраненного поиска:
Условия поиска:
Тестовые условия поиска
Электронная почта:
(изменить)
Который день?
Первое воскресеньеПервый понедельникПервый вторникПервая средаПервый четвергПервая пятницаПервая субботаПервый деньПервый рабочий день
Который день?
ВоскресеньеПонедельникВторникСредаЧетвергПятницаСуббота
Формат отчета:
РезюмеРезюме (текст)АбстрактАбстракт (текст)PubMed
Отправить не более:
1 шт. 5 шт. 10 шт. 20 шт. 50 шт. 100 шт. 200 шт.
5 шт. 10 шт. 20 шт. 50 шт. 100 шт. 200 шт.
Отправить, даже если нет новых результатов
Необязательный текст в электронном письме:
Создайте файл для внешнего программного обеспечения для управления цитированием
. 1991 июнь; 19 (1): 14.
А А Осоро
PMID:
1960918
А А Осоро.
Кения Нурс Дж.
1991 июнь
. 1991 июнь; 19 (1): 14.
Автор
А А Осоро
PMID:
1960918
Абстрактный
Картинка в картинке:
Быстрый рост населения является одним из основных факторов, способствующих бедности и отсталости стран третьего мира, особенно африканских стран, которые могут похвастаться самыми высокими темпами роста населения в мире. Быстрый рост обусловлен несколькими факторами: снижением уровня смертности, молодым населением, повышением уровня жизни, а также отношением и практикой, способствующими высокой рождаемости. Африканцы рассматривают большие семьи как экономический актив и как символ достоинства и чести, а родители видят в них безопасность в старости. Идеальный размер семьи в Африке — от 5 до 7 детей. Из-за его сложных причин обуздать быстрый рост нелегко. Помимо стратегических трудностей, демографическая политика обычно встречает сопротивление, часто со стороны религиозных групп. Таким образом, чтобы получить признание, программы народонаселения должны быть интегрированы с текущими программами развития сообщества. Несмотря на то, что это часто вызывает оппозицию, планирование семьи имеет более важное значение, чем когда-либо, поскольку быстрый рост населения продолжает создавать взрывоопасную ситуацию. Быстрый рост привел к неконтролируемой урбанизации, которая привела к перенаселенности, нищете, преступности, загрязнению и политическим беспорядкам.
Быстрый рост обусловлен несколькими факторами: снижением уровня смертности, молодым населением, повышением уровня жизни, а также отношением и практикой, способствующими высокой рождаемости. Африканцы рассматривают большие семьи как экономический актив и как символ достоинства и чести, а родители видят в них безопасность в старости. Идеальный размер семьи в Африке — от 5 до 7 детей. Из-за его сложных причин обуздать быстрый рост нелегко. Помимо стратегических трудностей, демографическая политика обычно встречает сопротивление, часто со стороны религиозных групп. Таким образом, чтобы получить признание, программы народонаселения должны быть интегрированы с текущими программами развития сообщества. Несмотря на то, что это часто вызывает оппозицию, планирование семьи имеет более важное значение, чем когда-либо, поскольку быстрый рост населения продолжает создавать взрывоопасную ситуацию. Быстрый рост привел к неконтролируемой урбанизации, которая привела к перенаселенности, нищете, преступности, загрязнению и политическим беспорядкам.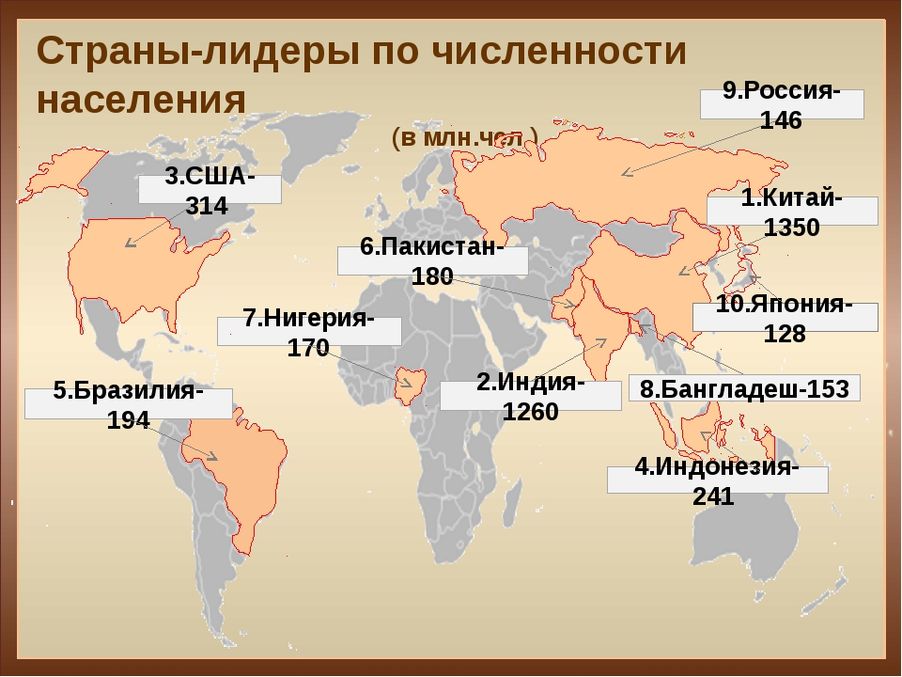 Быстрый рост опережает рост производства продовольствия, а рост населения приводит к чрезмерному использованию пахотных земель и их уничтожению. Быстрый рост также препятствует экономическому развитию и вызывает массовую безработицу. 45% рабочей силы Кении не имеют работы. В конечном итоге быстрый рост подорвал качество жизни людей. Ответственность общества выходит за рамки простого обеспечения выживания населения. Общество должно стремиться обеспечить людям хорошую жизнь – достойную.
Быстрый рост опережает рост производства продовольствия, а рост населения приводит к чрезмерному использованию пахотных земель и их уничтожению. Быстрый рост также препятствует экономическому развитию и вызывает массовую безработицу. 45% рабочей силы Кении не имеют работы. В конечном итоге быстрый рост подорвал качество жизни людей. Ответственность общества выходит за рамки простого обеспечения выживания населения. Общество должно стремиться обеспечить людям хорошую жизнь – достойную.
Похожие статьи
Рост населения и снабжение продовольствием в странах Африки к югу от Сахары.
Мирман Дж., Кокрейн С.Х.
Мирман Дж. и др.
Финансы Дев. 1982 сен; 19 (3): 12-7.
Финансы Дев. 1982.PMID: 12264271
Рост населения и развитие: опыт Кении.
Ньямванге М.
Ньямванге М.
Сканд Джей Дев Альтерн. 1995 март-июнь;14(1-2):149-60.
Сканд Джей Дев Альтерн. 1995.PMID: 12291578
[Продовольствие и население: исследование трех стран].
Кризисный комитет по народонаселению PCC.
Кризисный комитет по народонаселению PCC.
Профамилия. 1988 декабрь; 4 (13): 35-47.
Профамилия. 1988 год.PMID: 12157691
Испанский язык.
Рост населения и ухудшение состояния окружающей среды в Малави.
Калипени Э.
Калипени Э.
Афр Инсайт. 1992;22(4):273-82.
Афр Инсайт. 1992.PMID: 12288851
Программы снижения рождаемости должны сопровождать земельные реформы.
Атику Дж.
Атику Дж.
Здоровье женщин. 1994 июль-сен;2(3):16-20.
Здоровье женщин. 1994.PMID: 12318956
Посмотреть все похожие статьи
термины MeSH
Процитируйте
Формат:
ААД
АПА
МДА
НЛМ
Отправить по телефону
3. Популяции и образцы
Население
В статистике термин «население» имеет несколько иное значение, чем то, которое ему придается в обычной речи. Это не обязательно должно относиться только к людям или к одушевленным существам — например, к населению Британии или популяции собак в Лондоне. Статистики также говорят о совокупности объектов, событий, процедур или наблюдений, включая такие вещи, как количество свинца в моче, визиты к врачу или хирургические операции. Таким образом, население представляет собой совокупность существ, вещей, случаев и т. д.
Таким образом, население представляет собой совокупность существ, вещей, случаев и т. д.
Хотя статистик должен четко определить совокупность, с которой он имеет дело, он может быть не в состоянии точно ее подсчитать. Например, в обычном употреблении население Англии обозначает количество людей в пределах границ Англии, возможно, по данным переписи. Но врач может начать исследование, чтобы попытаться ответить на вопрос: «Каково среднее систолическое артериальное давление у англичан в возрасте 40–59 лет?» Но кто такие «англичане», о которых здесь идет речь? Не все англичане живут в Англии, и социальное и генетическое происхождение тех, кто живет, может различаться. Хирург может изучить последствия двух альтернативных операций при язве желудка. Но сколько лет пациентам? Какого они пола? Насколько серьезна их болезнь? Где они живут? И так далее. Читателю нужна точная информация по таким вопросам, чтобы сделать обоснованные выводы из изученной выборки относительно рассматриваемой совокупности. Статистические данные, такие как средние значения и стандартные отклонения, взятые из совокупности, называются параметрами совокупности. Они часто обозначаются греческими буквами: среднее значение генеральной совокупности обозначается μ(mu), а стандартное отклонение обозначается ς (сигма в нижнем регистре)
Статистические данные, такие как средние значения и стандартные отклонения, взятые из совокупности, называются параметрами совокупности. Они часто обозначаются греческими буквами: среднее значение генеральной совокупности обозначается μ(mu), а стандартное отклонение обозначается ς (сигма в нижнем регистре)
Образцы
Популяция обычно содержит слишком много особей для удобного изучения, поэтому исследование часто ограничивается одной или несколькими выборками, взятыми из нее. Хорошо подобранная выборка будет содержать большую часть информации о конкретном параметре совокупности, но отношение между выборкой и совокупностью должно быть таким, чтобы можно было сделать верные выводы о совокупности на основе этой выборки.
Следовательно, первым важным свойством выборки является то, что каждый индивидуум в совокупности, из которой она составлена, должен иметь известный ненулевой шанс быть включенным в нее; естественно предположить, что эти шансы должны быть равными. Мы хотели бы, чтобы выбор был сделан независимо; другими словами, выбор одного предмета не повлияет на вероятность выбора других предметов. Чтобы убедиться в этом, мы делаем выбор с помощью процесса, в котором действует только случайность, такого как вращение монеты или, что чаще, использование таблицы случайных чисел. Ограниченная таблица приведена в Таблице F (Приложение), а более обширные таблицы были опубликованы (1-4). Выбранная таким образом выборка называется случайной выборкой. способ, которым он выбран.
Чтобы убедиться в этом, мы делаем выбор с помощью процесса, в котором действует только случайность, такого как вращение монеты или, что чаще, использование таблицы случайных чисел. Ограниченная таблица приведена в Таблице F (Приложение), а более обширные таблицы были опубликованы (1-4). Выбранная таким образом выборка называется случайной выборкой. способ, которым он выбран.
Составление удовлетворительной выборки иногда представляет большие проблемы, чем статистический анализ сделанных на ней наблюдений. Полное обсуждение этой темы выходит за рамки этой книги, но руководство легко доступно (1) (2). В этой книге предлагается только введение.
Перед взятием образца исследователь должен определить совокупность, из которой он должен быть получен. Иногда он может полностью перечислить его членов до начала анализа – например, все печени, исследованные при вскрытии за предыдущий год, все пациенты в возрасте 20-44 лет, поступившие в стационар с прободной язвой за предыдущие 20 месяцев. В ретроспективных исследованиях такого рода номера могут последовательно присваиваться каждому пациенту или образцу, начиная с любой точки таблицы. Предположим, у нас есть популяция размером 150 человек, и мы хотим взять выборку размера пять. содержит набор сгенерированных компьютером случайных цифр, расположенных в группах по пять. Выберите любую строку и столбец, скажем, последний столбец из пяти цифр. Прочитайте только первые три цифры и спуститесь по столбцу, начиная с первой строки. Таким образом, у нас есть 265, 881, 722 и т. д. Если число находится между 001 и 150, мы включаем его в нашу выборку. Таким образом, по порядку в выборке будут испытуемые под номерами 24, 59., 107, 73 и 65. При необходимости мы можем продолжить вниз по следующему столбцу слева, пока не будет выбрана полная выборка.
В ретроспективных исследованиях такого рода номера могут последовательно присваиваться каждому пациенту или образцу, начиная с любой точки таблицы. Предположим, у нас есть популяция размером 150 человек, и мы хотим взять выборку размера пять. содержит набор сгенерированных компьютером случайных цифр, расположенных в группах по пять. Выберите любую строку и столбец, скажем, последний столбец из пяти цифр. Прочитайте только первые три цифры и спуститесь по столбцу, начиная с первой строки. Таким образом, у нас есть 265, 881, 722 и т. д. Если число находится между 001 и 150, мы включаем его в нашу выборку. Таким образом, по порядку в выборке будут испытуемые под номерами 24, 59., 107, 73 и 65. При необходимости мы можем продолжить вниз по следующему столбцу слева, пока не будет выбрана полная выборка.
Использование случайных чисел таким образом, как правило, предпочтительнее, чем брать каждого другого пациента или каждый пятый образец или действовать по какому-то другому регулярному плану. Регулярность плана может иногда случайно совпадать с какой-то непредвиденной регулярностью в подаче материала для исследования — например, приемы пациентов из определенных практик в определенные дни недели или образцы, приготовленные партиями в по какому-то расписанию.
Регулярность плана может иногда случайно совпадать с какой-то непредвиденной регулярностью в подаче материала для исследования — например, приемы пациентов из определенных практик в определенные дни недели или образцы, приготовленные партиями в по какому-то расписанию.
Поскольку восприимчивость к заболеванию обычно зависит от возраста, пола, рода занятий, семейного анамнеза, подверженности риску, состояния прививки, страны проживания или посещения, а также многих других генетических или экологических факторов, рекомендуется исследовать образцы, взятые в посмотреть, сопоставимы ли они в среднем в этих отношениях. Случайный процесс отбора предназначен для того, чтобы сделать их таковыми, но иногда он может случайно привести к несоответствию. Чтобы предотвратить такую возможность, выборка может быть стратифицирована. Это означает, что сначала закладывается структура, а затем пациенты или объекты исследования в случайной выборке распределяются по отсекам структуры. Например, структура может иметь первичное деление на мужчин и женщин, а затем вторичное деление каждой из этих категорий на пять возрастных групп, в результате чего получается структура с десятью отсеками. При этом важно иметь в виду, что распределения категорий в двух выборках, составленных на основе такой схемы, могут быть действительно сопоставимы, но они не будут отражать распределение этих категорий в генеральной совокупности, из которой составлена выборка, за исключением случаев, когда компартменты в рамках были разработаны с учетом этого. Например, в категории мужчин и женщин может быть допущено равное количество мужчин и женщин, но мужчин и женщин не одинаково много в общей популяции, и их относительные пропорции меняются с возрастом. Это известно как стратифицированная случайная выборка. Для взятия выборки из длинного списка компромисс между строгой теорией и практичностью известен как систематическая случайная выборка. но мы выбираем начальную точку в пределах первого интервала случайным образом.
При этом важно иметь в виду, что распределения категорий в двух выборках, составленных на основе такой схемы, могут быть действительно сопоставимы, но они не будут отражать распределение этих категорий в генеральной совокупности, из которой составлена выборка, за исключением случаев, когда компартменты в рамках были разработаны с учетом этого. Например, в категории мужчин и женщин может быть допущено равное количество мужчин и женщин, но мужчин и женщин не одинаково много в общей популяции, и их относительные пропорции меняются с возрастом. Это известно как стратифицированная случайная выборка. Для взятия выборки из длинного списка компромисс между строгой теорией и практичностью известен как систематическая случайная выборка. но мы выбираем начальную точку в пределах первого интервала случайным образом.
Беспристрастность и точность
Термины «непредвзятость» и «точность» приобрели в статистике особое значение. Когда мы говорим, что измерение несмещено, мы имеем в виду, что среднее значение большого набора несмещенных измерений будет близко к истинному значению. Когда мы говорим, что оно точное, мы имеем в виду, что оно повторяемо. Повторные измерения будут близкими друг к другу, но не обязательно близкими к истинному значению. Мы хотели бы, чтобы измерение было точным и точным. Некоторые авторы приравнивают беспристрастность к точности, но это не является универсальным, а другие используют термин точность для обозначения измерения, которое является одновременно и беспристрастным, и точным. Страйк (5) дает хорошее обсуждение проблемы.
Когда мы говорим, что оно точное, мы имеем в виду, что оно повторяемо. Повторные измерения будут близкими друг к другу, но не обязательно близкими к истинному значению. Мы хотели бы, чтобы измерение было точным и точным. Некоторые авторы приравнивают беспристрастность к точности, но это не является универсальным, а другие используют термин точность для обозначения измерения, которое является одновременно и беспристрастным, и точным. Страйк (5) дает хорошее обсуждение проблемы.
Известно, что оценка параметра, взятая из случайной выборки, несмещена. По мере увеличения размера выборки она становится более точной.
Рандомизация
Таблицы случайных чисел также используются для рандомизации назначения лечения пациентам в клинических испытаниях. Это гарантирует отсутствие предвзятости при назначении лечения и, в долгосрочной перспективе, субъекты в каждой группе лечения сопоставимы как по известным, так и по неизвестным прогностическим факторам. Распространенным методом является использование блокированной рандомизации. Это делается для того, чтобы через равные промежутки времени в двух группах было равное количество. Обычные размеры блоков: два, четыре, шесть, восемь и десять. Предположим, мы выбрали размер блока десять. Простой метод с использованием Таблицы F (Приложение) состоит в том, чтобы выбрать первые пять уникальных цифр в любой строке. Если мы выберем первую строку, первые пять уникальных цифр будут 3, 5, 6, 8 и 4. Таким образом, мы отнесем третьего, четвертого, пятого, шестого и восьмого испытуемых к одному лечению, а первого, второго, седьмого. , девятый и десятый к другому. Если бы размер блока был меньше десяти, мы бы проигнорировали цифры, превышающие размер блока. Чтобы назначить дальнейшие объекты для лечения, мы продолжаем в том же ряду, выбирая следующие пять уникальных цифр для первого лечения. В рандомизированных контролируемых исследованиях рекомендуется время от времени менять размер блока, чтобы было труднее угадать, каким будет следующее лечение.
Это делается для того, чтобы через равные промежутки времени в двух группах было равное количество. Обычные размеры блоков: два, четыре, шесть, восемь и десять. Предположим, мы выбрали размер блока десять. Простой метод с использованием Таблицы F (Приложение) состоит в том, чтобы выбрать первые пять уникальных цифр в любой строке. Если мы выберем первую строку, первые пять уникальных цифр будут 3, 5, 6, 8 и 4. Таким образом, мы отнесем третьего, четвертого, пятого, шестого и восьмого испытуемых к одному лечению, а первого, второго, седьмого. , девятый и десятый к другому. Если бы размер блока был меньше десяти, мы бы проигнорировали цифры, превышающие размер блока. Чтобы назначить дальнейшие объекты для лечения, мы продолжаем в том же ряду, выбирая следующие пять уникальных цифр для первого лечения. В рандомизированных контролируемых исследованиях рекомендуется время от времени менять размер блока, чтобы было труднее угадать, каким будет следующее лечение.
Важно понимать, что пациенты в рандомизированном исследовании представляют собой не случайную выборку из популяции людей с рассматриваемым заболеванием, а скорее тщательно отобранную группу подходящих и желающих пациентов.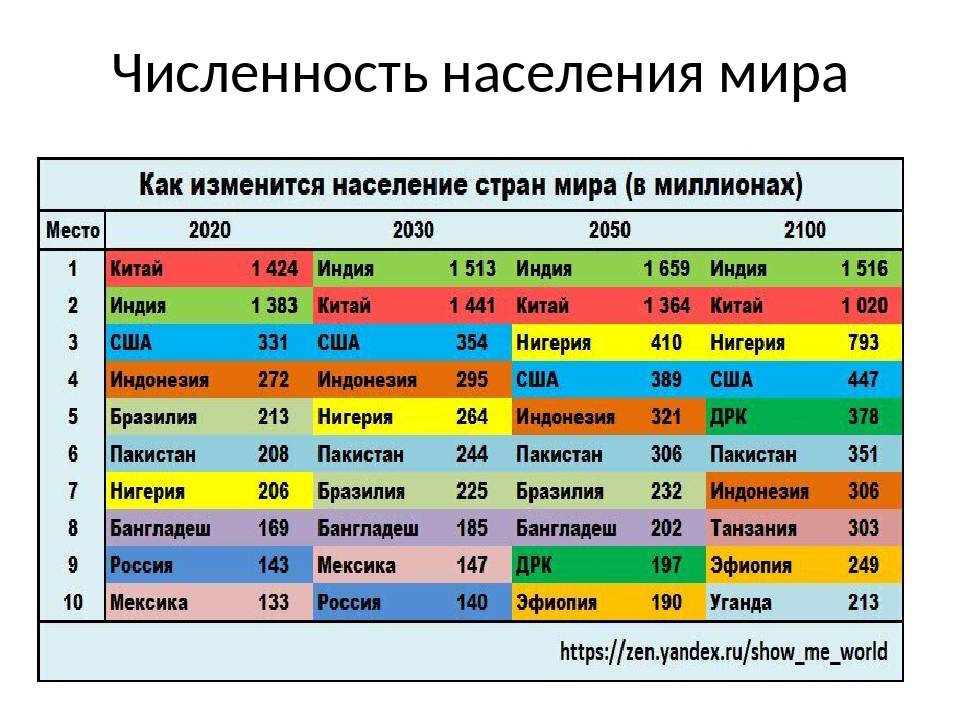 Однако рандомизация гарантирует, что в долгосрочной перспективе любые различия в результатах в двух группах лечения будут связаны исключительно с различиями в лечении.
Однако рандомизация гарантирует, что в долгосрочной перспективе любые различия в результатах в двух группах лечения будут связаны исключительно с различиями в лечении.
Вариация между выборками
Даже если мы гарантируем, что каждый член генеральной совокупности имеет известный и обычно равный шанс быть включенным в выборку, из этого не следует, что ряд выборок, взятых из одной генеральной совокупности и удовлетворяющих этому критерий будет одинаковым. Они будут показывать случайные вариации от одного к другому, и вариация может быть незначительной или значительной. Например, серия образцов температуры тела здоровых людей показала бы очень мало различий между образцами, но разница между образцами систолического артериального давления была бы значительной. Таким образом, вариации между выборками частично зависят от количества вариаций в генеральной совокупности, из которой они взяты.
Кроме того, общеизвестно, что небольшая выборка является гораздо менее надежным ориентиром для совокупности, из которой она была составлена, чем большая выборка. Другими словами, чем больше членов совокупности включено в выборку, тем больше шансов, что эта выборка будет точно представлять совокупность, при условии, что для построения выборки используется случайный процесс. Следствием этого является то, что если из совокупности берутся две или более выборки, чем они больше, тем больше вероятность того, что они будут похожи друг на друга — опять же при условии, что используется метод случайной выборки. Таким образом, различия между выборками частично зависят также от размера выборки. Однако обычно мы не в состоянии взять случайную выборку; наша выборка — это просто те предметы, которые доступны для изучения. Это «удобный» образец. Чтобы сделать обоснованные обобщения, мы хотели бы утверждать, что наша выборка в некотором роде репрезентативна для населения в целом, и по этой причине первым этапом отчета является описание выборки, скажем, по возрасту, полу и статусу заболевания. , чтобы другие читатели могли решить, репрезентативен ли он для типа пациентов, с которыми они сталкиваются.
Другими словами, чем больше членов совокупности включено в выборку, тем больше шансов, что эта выборка будет точно представлять совокупность, при условии, что для построения выборки используется случайный процесс. Следствием этого является то, что если из совокупности берутся две или более выборки, чем они больше, тем больше вероятность того, что они будут похожи друг на друга — опять же при условии, что используется метод случайной выборки. Таким образом, различия между выборками частично зависят также от размера выборки. Однако обычно мы не в состоянии взять случайную выборку; наша выборка — это просто те предметы, которые доступны для изучения. Это «удобный» образец. Чтобы сделать обоснованные обобщения, мы хотели бы утверждать, что наша выборка в некотором роде репрезентативна для населения в целом, и по этой причине первым этапом отчета является описание выборки, скажем, по возрасту, полу и статусу заболевания. , чтобы другие читатели могли решить, репрезентативен ли он для типа пациентов, с которыми они сталкиваются.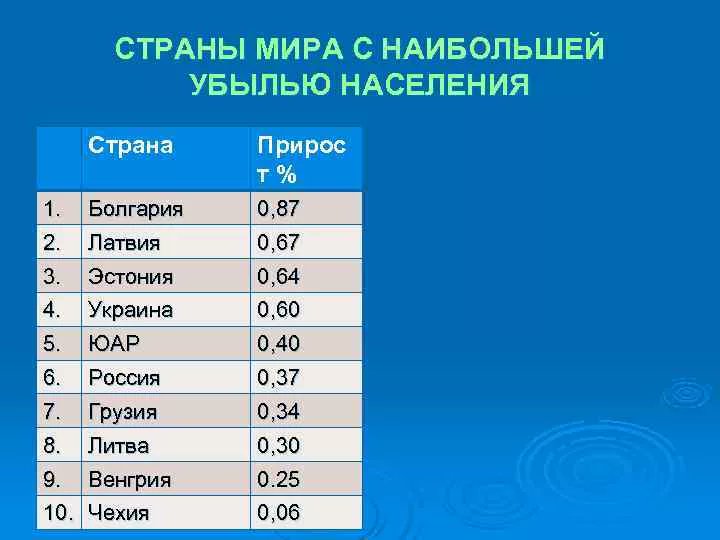
Стандартная ошибка среднего
Если мы возьмем серию выборок и вычислим среднее значение наблюдений в каждой, мы получим ряд средних значений. Эти средние обычно соответствуют нормальному распределению, и они часто соответствуют ему, даже если наблюдения, из которых они были получены, не соответствуют ему (см. упражнение 3.3). Это может быть доказано математически и известно как «центральная предельная теорема». Ряд средних значений, как и ряд наблюдений в каждой выборке, имеет стандартное отклонение. Стандартная ошибка среднего значения одной выборки — это оценка стандартного отклонения, которое может быть получено из средних значений большого количества выборок, взятых из этой совокупности.
Как отмечалось выше, если случайные выборки взяты из населения, их средние значения будут варьироваться от одного к другому. Вариация зависит от вариации генеральной совокупности и размера выборки. Нам неизвестна изменчивость генеральной совокупности, поэтому мы используем изменчивость выборки в качестве ее оценки. Это выражается в стандартном отклонении. Если теперь мы разделим стандартное отклонение на квадратный корень из числа наблюдений в выборке, мы получим оценку стандартной ошибки среднего значения . Важно понимать, что нам не нужно брать повторные выборки, чтобы оценить стандартную ошибку, достаточно информации в рамках одной выборки. Однако концепция состоит в том, что если бы мы брали повторяющиеся случайные выборки из населения, мы ожидали бы, что среднее значение изменится именно так, чисто случайно.
Это выражается в стандартном отклонении. Если теперь мы разделим стандартное отклонение на квадратный корень из числа наблюдений в выборке, мы получим оценку стандартной ошибки среднего значения . Важно понимать, что нам не нужно брать повторные выборки, чтобы оценить стандартную ошибку, достаточно информации в рамках одной выборки. Однако концепция состоит в том, что если бы мы брали повторяющиеся случайные выборки из населения, мы ожидали бы, что среднее значение изменится именно так, чисто случайно.
Практика врача общей практики в Йоркшире включает часть города с большой типографией и часть прилегающей территории с овцеводством. С информированного согласия своих пациентов она исследовала, различается ли диастолическое артериальное давление мужчин в возрасте 20-44 лет у печатников и сельскохозяйственных рабочих. Для этой цели она взяла случайную выборку из 72 печатников и 48 сельскохозяйственных рабочих и рассчитала среднее значение и стандартное отклонение, как показано в таблице 3. 1.
1.
Для расчета стандартных ошибок двух средних значений артериального давления стандартное отклонение каждой выборки делится на квадратный корень из числа наблюдений в выборке.
Эти стандартные ошибки могут быть использованы для изучения значимости разницы между двумя средними значениями, как описано в последующих главах
Таблица 3.1
Стандартная ошибка пропорции или процента со средним значением, чтобы мы могли также рассчитать стандартную ошибку, связанную с процентом или долей. Здесь размер выборки будет влиять на размер стандартной ошибки, но величина вариации определяется значением процента или доли в самой совокупности, поэтому нам не нужна оценка стандартного отклонения. Например, старший хирургический регистратор в крупной больнице исследует острый аппендицит у людей в возрасте 65 лет и старше. В качестве предварительного исследования он изучает истории болезни за предыдущие 10 лет и находит, что из 120 пациентов этой возрастной группы с диагнозом, подтвержденным на операции, 73 (60,8%) были женщинами и 47 (39).
 0,2%) были мужчинами.
0,2%) были мужчинами.
Если p представляет один процент, 100 p представляет другой. Затем стандартная ошибка каждого из этих процентов получается путем (1) их умножения, (2) деления произведения на число в выборке и (3) извлечения квадратного корня:
, что для данных об аппендиците, приведенных выше выглядит следующим образом:
Проблемы с неслучайными выборками
В общем, у нас нет такой роскоши, как случайная выборка; нам приходится обходиться тем, что есть в наличии, а « удобства образца ». Чтобы иметь возможность делать обобщения, мы должны исследовать, не могли ли закраться предубеждения, которые означают, что имеющиеся пациенты не являются типичными. Общие предубеждения:
- больничные пациенты не такие, как в обществе;
- волонтеры не типичны для недобровольцев;
- пациентов, которые возвращают анкеты, отличаются от тех, кто этого не делает.
Чтобы убедить читателя в том, что включенные пациенты являются типичными, важно в начале отчета дать как можно больше подробностей о процессе отбора и некоторых демографических данных, таких как возраст, пол, социальный класс и процент ответивших.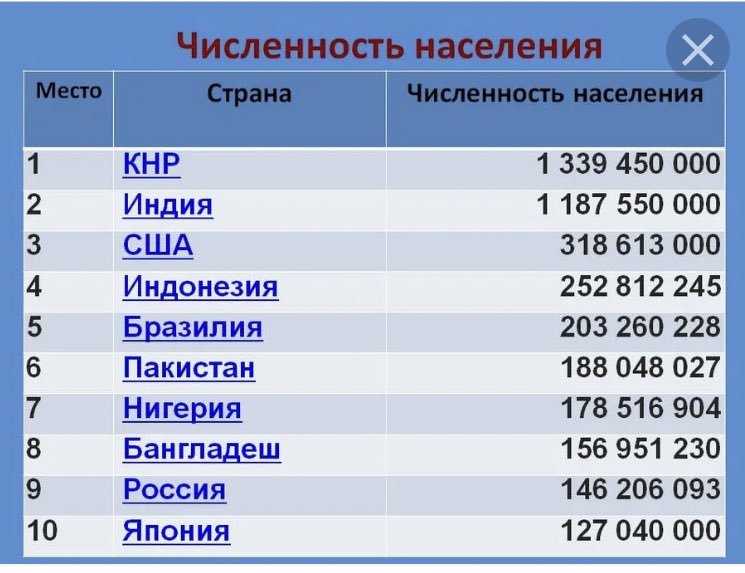 .
.
Общие вопросы
Учитывая измерения на образце, в чем разница между стандартным отклонением и стандартной ошибкой?
Стандартное отклонение — это выборочная оценка параметра генеральной совокупности; то есть это оценка изменчивости наблюдений. Поскольку совокупность уникальна, она имеет уникальное стандартное отклонение, которое может быть большим или малым в зависимости от того, насколько изменчивы наблюдения. Мы не ожидаем, что стандартное отклонение выборки станет меньше, потому что выборка станет больше. Однако большая выборка даст более точную оценку стандартного отклонения генеральной совокупности, чем небольшая выборка.
Стандартная ошибка, с другой стороны, является мерой точности оценки параметра генеральной совокупности. К параметру всегда прилагается стандартная ошибка, и могут быть стандартные ошибки любой оценки, например среднего, медианы, пятого центиля, даже стандартной ошибки стандартного отклонения. Поскольку можно было бы ожидать, что точность оценки будет увеличиваться с увеличением размера выборки, стандартная ошибка оценки будет уменьшаться по мере увеличения размера выборки.
Когда следует использовать стандартное отклонение для описания данных и когда следует использовать стандартную ошибку?
Распространенной ошибкой является попытка использовать стандартную ошибку для описания данных. Обычно это делается потому, что стандартная ошибка меньше, и поэтому исследование выглядит более точным. Если цель состоит в том, чтобы описать данные (например, чтобы можно было увидеть, являются ли пациенты типичными) и если данные являются правдоподобными нормальными, то следует использовать стандартное отклонение (мнемоника D для описания и D для отклонения). Если целью является описание результатов исследования, например, для оценки распространенности заболевания или среднего роста группы, то следует использовать стандартную ошибку (или, лучше, доверительный интервал; см. главу 4). (мнемоника E для оценки и E для ошибки).
Ссылки
- Альтман Д.Г. Практическая статистика для медицинских исследований. London: Chapman & Hall, 1991
- Armitage P, Berry G.

Leave a Reply