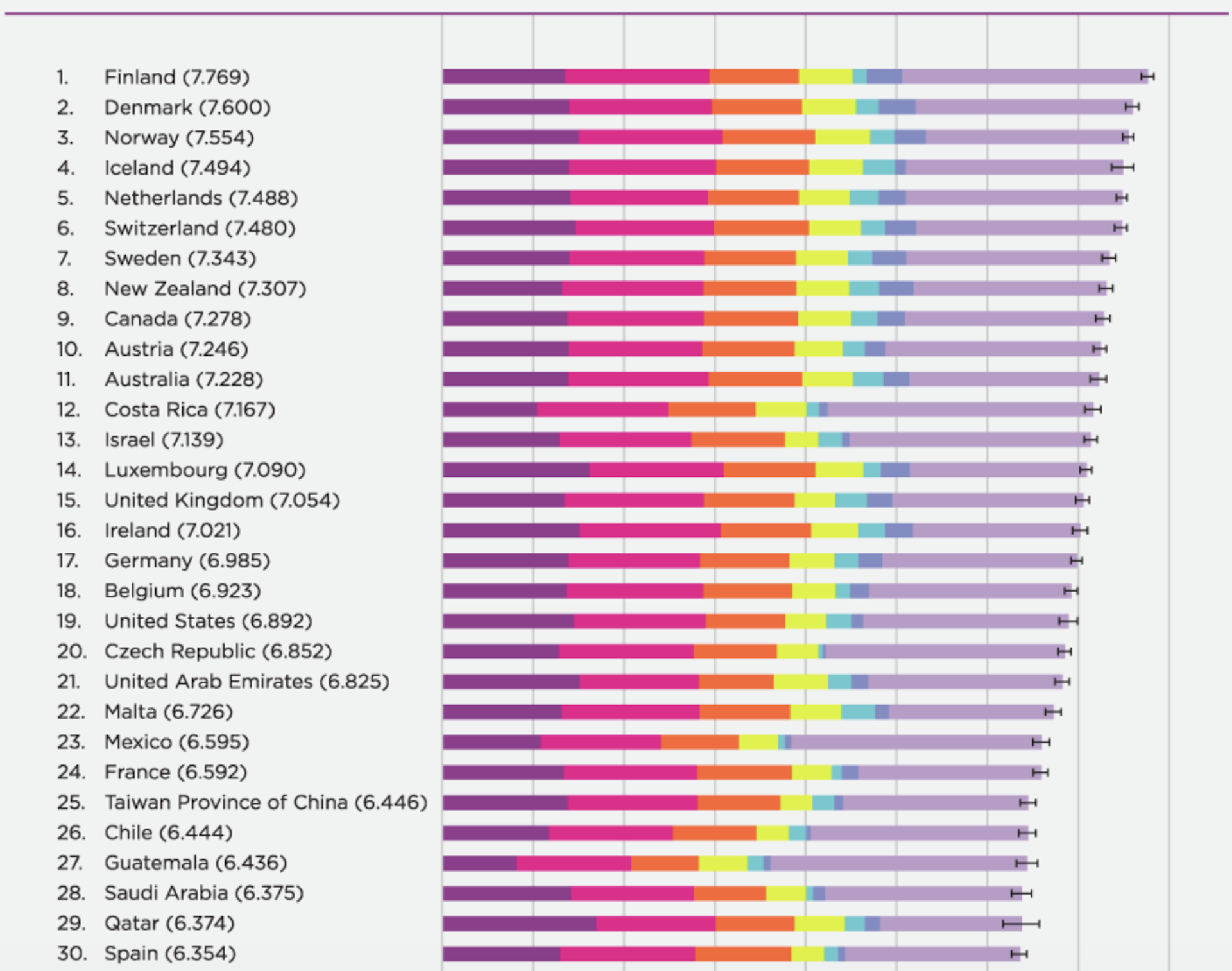
Исследование качества информации и достоверности источников в Википедии / Хабр
Возможно для кого-то это будет удивительно и даже возмутительно, но в Википедии информация не должна быть правдивой, важно, чтобы она была подтверждена достоверными источниками. Именно проблеме дезинформации и достоверности источников в Википедии был посвящён последний выпуск уходящего 2020 года Wikimedia Research Showcase. Это ежемесячное публичное мероприятие, на котором представляются последние работы исследовательской группы Фонда Викимедиа и приглашенных докладчиков из академического сообщества. Мне была предоставлена возможность рассказать о последних научных работах, проведённых совместно с сотрудниками нашей кафедры. В этой статье на Хабре я постараюсь коротко описать последние исследования нашей кафедры в области оценки качества информации и достоверности источников в многоязычной Википедии. Дополнительно представлены общедоступные инструменты для оценки качества и достоверности, основанные на научных исследованиях.
Исследование качества информации и достоверности источников в Википедии
Видеотрансляция декабрьского выпуска 2020 года Wikimedia Research Showcase доступна на YouTube, а слайды с презентации размещены на SlideShare и figshare.
Многоязычность Википедии
Согласно Ethnologue, в мире люди разговаривают на более чем 7 тыс. языках, из которых почти 3 тыс. под угрозой исчезновения. Для сравнения, статьи Википедии доступны на 314 языках.
Более половины населения Земли разговаривает только на 23 языках. Самым популярным является английский, на нём разговаривает около 1.27 млрд человек. Однако, для более чем 70% из них — английский не является родным.
В своей научной диссертации, которая была защищена в марте 2019 года в польском университете, я описал метод сравнения и обогащения информации в многоязычных сайтах вики, основанный на анализе их качества. В качестве примера рассматривался наиболее популярный сайт вики – Википедия. Для проверки предложенного метода рассматривались 5 языковых разделов Википедии – английский, белорусский, польский, русский, украинский.
Пример обогащения белорусской Википедии инфобоксом с описанием Экономического Университета в Познани.
Знание этих языков и результаты исследований позволили мне прийти к выводу, что предложенные в диссертации алгоритмы можно использовать и для других языковых версий этой свободной энциклопедии (а также для других сайтов вики).
Википедию можно редактировать на каждом языке независимо, что приводит к таким проблемам как:
один и тот же объект (город, персона, событие и т.п.) можно описать по-разному,
пользователю обычно необходимо понимать эти языки для проверки/сравнения информации.
Дополнительно, сама оценка качества информации субъективна и зависит от языка Википедии:
Одним из важных критериев качества информации в Википедии является наличие достоверных источников. Однако, оценка одного и того же источника зависит от языковой версии Википедии. Дополнительная проблема — надежность одного и того же источника может со временем измениться.
Оценка качества информации в Википедии
Каждое языковое издание Википедии может определять собственную систему оценок качества для статей. Часто каждая языковая версия имеет специальную отметку для статей, которые считаются лучшими — «Избранные статьи». Также есть отметка за качественные достойные статьи, не соответствующие критериям Избранных статей — они называются «Хорошие статьи».
В некоторых языковых версиях Википедии есть также другие оценки качества, которые могут отражать «зрелость» статьи. В английской Википедии, помимо наивысших оценок «FA» и «GA», есть ещё «A-класс», «B-класс», «C-класс», «Старт» и «Заглушка». В русской Википедии дополнительно к двум наивысшим оценкам есть ещё «Добротная статья», «I уровень», «II уровень», «III уровень» и «IV уровень». В польской Википедии есть три дополнительных класса: «Четверка», «Старт» и «Заглушка».
Несмотря на одинаковые названия, эквивалентные классы между языковыми версиями могут иметь различия в оценке стандартов. Например, в некоторых языковых версиях для высоких оценок существует ограничение на длину статьи. Следовательно, для каждой языковой версии может быть своя собственная модель качества, даже если у этих языков одинаковое количество оценок.
Например, в некоторых языковых версиях для высоких оценок существует ограничение на длину статьи. Следовательно, для каждой языковой версии может быть своя собственная модель качества, даже если у этих языков одинаковое количество оценок.
Дополнительная проблема — большое количество статей, не имеющих оценки качества. Некоторые языковые версии содержат более 90% неоцененных статей. Ниже представлена сравнительная таблица для некоторых языковых разделов Википедий (по порядку: белорусский, немецкий, английский, французский, польский, русский, украинский).
Классификация качества в разных языковых разделах Википедии
Чтобы определить параметры качества в Википедии, следует принять во внимание сходство этого веб-сайта с традиционными энциклопедиями и сайтами на технологии Веб 2.0. С одной стороны, контент в Википедии создан как ориентир в энциклопедическом стиле. С другой стороны, Википедия построена таким образом, чтобы пользователи могли сотрудничать и писать совместно материалы. Поэтому он основан на технологиях Веб 2.0.
Поэтому он основан на технологиях Веб 2.0.
На рисунке ниже показано покрытие между критериями качества сайтов Веб 2.0, традиционных энциклопедий и Википедии. Принимая во внимание критерии качества, принятые сообществом Википедии, мы можем выбрать следующие критерия (измерения) качества для статей Википедии: актуальность, достоверность, объективность, полнота, релевантность, стиль, читабельность.
Критерии качества. Источник: wikipediaquality.com
Актуальность: насколько статья описывает текущее состояние определенной реальности (степень актуальности/своевременности информации).
Достоверность: можно ли проверить предоставленную информацию из надежных источников.
Объективность: насколько содержание статьи соответствует критерию нейтральной точки зрения, содержит ли она изображения и другие мультимедийные материалы, относящиеся к этой статье.
Полнота: насколько исчерпывающим является описание темы в статье.

Релевантность: насколько статья важна для читателей/пользователей и соответствует его информационным нуждам.
Стиль: как организовано содержание статьи (наличие и размещение дополнительных комментариев, таблиц, изображений, звуковых файлов и др.).
Читабельность: насколько текст понятен и свободен от ненужной сложности.
Важные параметры качества
Используя алгоритмы машинного обучения, мы можем определить, какие параметры (характеристики) статей Википедии являются наиболее важными для оценки качества. Пример таких параметров: количество слов в тексте статьи, количество изображений, посещение статьи за определённый период времени, сколько раз статья была редактирована и др.
Шесть лет назад мы опубликовали результаты исследований, в которых показали, что показатели вместе с их значимостью образуют определенный профиль языка, то есть один параметр важен для одного языка, другой лучше характеризует качество информации другого языкового раздела Википедии. Затем можно сравнивать разные языки.
Затем можно сравнивать разные языки.
Другой пример — в моей диссертации было использовано более 100 параметров для построения моделей качества для разных языков. Рисунок ниже показывает важность выбранных показателей в моделях прогнозирования качества в английской и русской Википедии.
Синтетический показатель качества
Мы обнаружили, что некоторые из показателей показали высокую важность при оценке качества статей на разных языках. Такие параметры обычно положительно коррелируют с оценками качества: длина статьи, количество изображений, примечаний (источников), разделов, авторов и др.
Шесть лет назад мы предложили способ оценки качества статей по непрерывной шкале (от 0 до 100), используя синтетический показатель качества, который включает в себя нормализованные значения важных параметров статей. Нормализация выбранных параметров зависит от языкового раздела Википедии, поскольку она использует пороговые значения, которые зависят от лучших статей в рассматриваемой языковой версии. Нормализация каждого параметра проводилась в соответствии со следующим правилом: если значение данного параметра на данном языке превышало пороговое значение медианного значения лучших статей в той же языковой версии, она принималась равной 100 баллам; в противном случае его значение линейно масштабировалось, чтобы отразить отношение значения параметра к среднему значению. Более подробную информацию об алгоритме и результатах его применения синтетического показателя качества на миллионах статей Википедии можно найти в научных публикациях в журналах Informatics и Computers.
Нормализация каждого параметра проводилась в соответствии со следующим правилом: если значение данного параметра на данном языке превышало пороговое значение медианного значения лучших статей в той же языковой версии, она принималась равной 100 баллам; в противном случае его значение линейно масштабировалось, чтобы отразить отношение значения параметра к среднему значению. Более подробную информацию об алгоритме и результатах его применения синтетического показателя качества на миллионах статей Википедии можно найти в научных публикациях в журналах Informatics и Computers.
Числовое значение качества статьи позволяет сравнивать качество статей даже между разными языковыми версиями Википедии. Это позволяет найти, какие темы (категорий) статей конкретного языкового раздела Википедии имеют информацию лучшего качества.
Оценки качества вместе с показателями популярности, цитируемости, интереса авторов могут использоваться для создания индивидуального профиля для каждой статьи Википедии в каждой языковой версии. Например, на рисунке ниже представлен такой профиль на портале ВикиРанк с информацией о качестве и популярности для статьи «Президентские выборы в США (2020)» в русскоязычной Википедии.
Например, на рисунке ниже представлен такой профиль на портале ВикиРанк с информацией о качестве и популярности для статьи «Президентские выборы в США (2020)» в русскоязычной Википедии.
Профиль статьи Википедии с оценкой качества и популярности. Источник: wikirank.net
Источники информации в Википедии
Одним из важнейших факторов, влияющих на качество статей в Википедии, является наличие достоверных источников. Следуя ссылкам в примечаниях (сносках), читатели могут проверить факты или найти более подробную информацию по описанной теме. В одной из наших последних работ мы проанализировали более 40 миллионов статей из 55 наиболее развитых языковых разделов Википедии, чтобы извлечь информацию о более чем 200 миллионах примечаний (источников) и найти самые популярные и достоверные источники.
В вышеупомянутой публикации, мы использовали разные способы нахождения и извлечения информации об источниках статей Википедии. Например, комплексное извлечение основывалось на исходном коде статей (вики-разметка). Наличие некоторых примечаний невозможно определить напрямую на основании исходного (вики) кода статей. Иногда информационные блоки или таблицы в статье Википедии представлены лишь как шаблоны (ссылки в коде, которые позволяют получить содержимое из других страниц Википедии). На рисунке показана такая ситуация на примере таблицы со ссылками в статье Википедии о пандемии коронавируса, которая была добавлена с использованием шаблона. В нашем комплексном подходе мы учитывали содержание таких шаблонов.
Наличие некоторых примечаний невозможно определить напрямую на основании исходного (вики) кода статей. Иногда информационные блоки или таблицы в статье Википедии представлены лишь как шаблоны (ссылки в коде, которые позволяют получить содержимое из других страниц Википедии). На рисунке показана такая ситуация на примере таблицы со ссылками в статье Википедии о пандемии коронавируса, которая была добавлена с использованием шаблона. В нашем комплексном подходе мы учитывали содержание таких шаблонов.
Следующий рисунок показывает наиболее часто используемые шаблоны в тегах «<ref>» в английской Википедии. Среди наиболее часто используемых шаблонов в языковых версиях этой Википедии: ’Cite web’, ’Cite news’, ’Cite book’, ’Cite journal’ и другие.
Наиболее распространённые шаблоны в примечаниях анлийской Википедии. Источник: https://doi.org/10.3390/info11050263
Для русскоязычной Википедии среди наиболее популярных шаблонов можно встретить такие как: «Статья», «Книга», «Публикация» и др. Следующий рисунок иллюстрирует наиболее часто используемые шаблоны в тегах «<ref>» в русской Википедии.
Следующий рисунок иллюстрирует наиболее часто используемые шаблоны в тегах «<ref>» в русской Википедии.
Для других языковых разделов Википедии подобные рисунки можно найти в дополнительных материалах к научной статье.
Шаблоны с библиографической информацией
Некоторые часто используемые шаблоны в примечаниях подробно описывают источник – могут содержать информацию об авторах, издателе, дате публикации и др. Например, для английской Википедии наиболее часто заполняемые параметры таких шаблонов представлены на рисунке:
Для русскоязычной Википедии аналогичные данные выглядят так:
Для других языковых разделов результаты подобных исследований можно найти на странице с дополнительными материалами.
После анализа таких шаблонов с библиографией мы можем найти, например, популярных издателей в английской Википедии. Учитывая более 18 миллионов таких шаблонов, которые имеют значение в параметре «publisher» (издатель) можно сгенерировать рисунок, который показывает наиболее часто используемых издателей в источниках в английской Википедии.
Некоторые из самых популярных шаблонов позволяют добавлять идентификаторы к источнику, такие как DOI, JSTOR, PMC, PMID, arXiv, ISBN, ISSN, OCLC и другие. Часто такие идентификаторы указывают на научный источник информации. Рисунок ниже показывает, какая часть примечаний в некоторых языковых разделах Википедии содержит информацию об источниках с идентификаторами DOI, ISBN, ISSN, PMID, PMC.
Результаты показывают, что наиболее часто используются идентификаторы ISBN и DOI. Однако в общей «массе» примечаний встречаются не чаще чем в 10% случаев. Важно отметить, что наблюдается постепенное увеличение доли ссылок на научные публикации.
Модели популярности и надежности источников Википедии
В нашем недавнем исследовании мы предложили десять моделей, связанных с популярностью и надежностью источников. В большинстве случаев источник означает сайт (домен или поддомен) из URL-адреса в примечаниях.
Модель F — основанная на частоте (F) использования источника.

Модель P — основана на совокупном количестве просмотров страниц (P) статьи, в которой появляется источник.
Модель PR — основанная на совокупных просмотрах страниц (P) статьи, в которой появляется источник, разделенный на количество ссылок (R) в этой статье.
Модель PL — основана на совокупном количестве просмотров страниц (P) статьи, в которой указан источник, разделенный на длину статьи (L).
Модели Pm, PmR, PmL — это модифицированные версии со средним значением ежедневных просмотров страниц.
В моделях A, AR, AL используется количество авторов.
Если говорить про математическую составляющую, то для примера приведу формулу рассчёта для модели PR:
где:
s — источник,
n — номер по порядку рассматриваемой статьи Википедии,
C(i) — общее количество примечаний (сносок) в i-той статье,
Сs(i) — количество ссылок, использующих источник s (например, домен в URL) в i-той статье,
V(i) — суммарное количество просмотров i-той статьи.

Более подробное описание моделей (в том числе математическую состовляющую) можно найти в научной публикации в журнале Information.
Рассмотрим модель F, которая показывает частоту использования источника, т.е. сколько ссылок содержит анализируемый домен в URL. Этот метод часто использовался в смежных научных работах. Здесь мы учитываем общее количество появлений такой ссылки, т.е. если один и тот же источник цитируется 3 раза, мы считаем частоту как 3.
Для английской Википедии наиболее часто используемые сайты в примечаниях представлены на рисунке ниже:
Если мы рассмотрим результаты оценки источников на основании модели PR, то лидеры в английской Википедии будут выглядеть немного иначе:
Для русской Википедии аналогичный рисунок с результатами подсчёта на основе модели F выглядит так:
Модель PR вносит свои корректировки лидерства источников для русскоязычной Википедии:
В дополнительных материалах к публикации можно найти более расширенные результаты для различных языковый версий с использованием модели F и модели PR.
Как видим в зависимости от модели оценки популярности и достоверности мы можем получить разные результаты для одного и того же источника. Исследования показали, насколько сильно могут отличаться оценки достоверности также в зависимости от языкового раздела. Ниже представлена сравнительная таблица позиций в рейтинге популярности и достоверности для четырёх источников: nytimes.com, spiegel.de, lemonde.fr, elpais.com. Каждый источник был оценен с точки зрения различных языковых разделов Википедии и разных моделей.
Если мы рассматриваем сайты (домены) как источники, то их количество достигает более миллиона. Часть результатов по оценке каждого источника Википедии размещена в проекте BestRef. Для каждого источника в данном проекте имеется отдельный профиль, где показаны результаты оценки с использованием различных моделей и в рамках каждого языкового раздела Википедии. Для вышеуказанных четырёх источников это соответственно nytimes.com, spiegel.de, lemonde.fr, elpais.com. Отдельно можно ознакомится со списком наиболее популярных и достоверных источников в рамках конкретного языкового раздела (например русской Википедии). Ниже приведён пример списка источников и профиля отдельного сайта.
Отдельно можно ознакомится со списком наиболее популярных и достоверных источников в рамках конкретного языкового раздела (например русской Википедии). Ниже приведён пример списка источников и профиля отдельного сайта.
Список источников и профиль. Источник: bestref.net
Используя разные модели популярности и достоверности, мы можем оценивать не только домены, но и отдельные типы источников. Например, на основании расширенной библиографической информации из шаблонов в примечаниях мы оценили всех издателей в источниках английской Википедии. В таблице ниже представлены самые популярные и достоверные издатели с позициями в рейтинге в зависимости от модели.
Инструменты для оценки качества информации и достоверности источников в Википедии
Результаты некоторых исследований были внедрены в отдельные общедоступные проекты. Более того, существуют даже расширения для браузеров, которые позволяют исследовать качество статей Википедии и их источников «на месте». Например, для исследования достоверности источников можно воспользоваться плагином BestRef для Chrome. Видео-презентация этого плагина:
Видео-презентация этого плагина:
Для оценки и сравнения качества и популярности статей Википедии можно использовать плагин ВикиРанк для Chrome и Firefox. Кратко, о том, как это работает, показано на этом видео.
Отдельно доступно расширение для оценки качества инфобоксов (информационных карточек) в браузере Chrome. На видео-презентации можно узнать, как это работает.
Что дальше?
Рассмотренные модели качества информации, популярности и достоверности источников могут помочь обогатить различные языковые версии Википедии и других баз знаний (таких как DBpedia, Викиданные) информацией более высокого качества. Некоторые из методов планируется интегрировать в проект GlobalFactSync (GFS). Цель проекта GFS — синхронизировать фактические данные во всех языковых разделах Википедии и Викиданных. Здесь фактические данные определяются как определенная «порция» информации, то есть значения данных, такие как «географические координаты», «население» (города), «даты рождения», «химические формулы», «участие в фильмах» или «место рождения», прикреплённые к объекту (в статье Википедия или элемент Викиданных) и в идеале со ссылкой на источник (происхождение этой информации).
Дополнительно, информация об оценке достоверности источников может помочь улучшить модели оценки качества статей в Википедии. Это может быть особенно полезно при сравнении несовпадающих фактов между языковыми версиями статей Википедии. Кроме того, одним из многообещающих направлений ближайших исследований является создание общедоступных инструментов, которые позволяли бы рекомендовать лучшие источники для отдельных утверждений и по выбранным темам в разных языковых разделах Википедии.
Предложенные в исследованиях модели не идеальны, и могут быть совершенствованы – тут огромное «поле для манёвров». Чем больше мы исследуем эту область, тем больше находим проблем и возможных способов их решения.
Более подробную информацию об исследованиях в этой области можно найти на сайте WikiQ. Если вас интересует эта тема — мы готовы рассмотреть сотрудничество в этом направлении. Вопросы и предложения можно оставлять на Хабре в комментариях или связаться другим способом.
Литература
Lewoniewski, W.
 , Węcel, K., Abramowicz, W. (2020). Modeling Popularity and Reliability of Sources in Multilingual Wikipedia. Information, 11(5), 263. doi: 10.3390/info11050263
, Węcel, K., Abramowicz, W. (2020). Modeling Popularity and Reliability of Sources in Multilingual Wikipedia. Information, 11(5), 263. doi: 10.3390/info11050263Lewoniewski, W., Węcel, K., Abramowicz, W. (2019). Multilingual ranking of Wikipedia articles with quality and popularity assessment in different topics. Computers, 8(3), 60. doi: 10.3390/computers8030060
Lewoniewski, W. (2019). Measures for quality assessment of articles and infoboxes in multilingual Wikipedia. In International Conference on Business Information Systems (pp. 619-633). Springer, Cham. doi: 10.1007/978-3-030-04849-5_53
Lewoniewski, W. (2018). The method of comparing and enriching information in multilingual wikis based on the analysis of their quality. PhD thesis
Lewoniewski, W., Węcel, K., Abramowicz, W. (2017). Relative quality and popularity evaluation of multilingual Wikipedia articles. Informatics 2017, 4(4), 43.
 doi: 10.3390/informatics4040043
doi: 10.3390/informatics4040043Lewoniewski, W. (2017). Enrichment of information in multilingual Wikipedia based on quality analysis. In International Conference on Business Information Systems (pp. 216-227). Springer, Cham. doi: 10.1007/978-3-319-69023-0_19
Lewoniewski, W., Węcel, K., Abramowicz, W. (2017). Analysis of references across Wikipedia languages. In International Conference on Information and Software Technologies (pp. 561-573). Springer, Cham. doi: 10.1007/978-3-319-67642-5_47
Фильм Хакер (2016) смотреть онлайн бесплатно в хорошем HD 1080 / 720 качестве
Фильм Хакер смотреть онлайн
2016
1 ч. 47 мин.
16+
США
Триллеры
Драмы
Криминал
FullHD
Трейлер
2016
1 ч. 47 мин.
16+
США
Триллеры
Драмы
Криминал
FullHD
Рейтинг
Иви
Каллэн МакОлифф
Лоррэйн Николсон
Дэниэл Эрик Голд
Клифтон Коллинз мл.
Захари Беннетт
Кристиан Трулсен
Джеймс Байрон
Дэррил Флэтмэн
Аллисон Прэтт
Международный проект, снятый при участии кинематографистов из США, Таиланда, Казахстана, Гонконга и Канады и основанный, по словам создателей, на реальных событиях. Режиссером картины стал Акан Сатаев, известный по криминальной драме «Рэкетир» и сериалу «Братья».
Еще будучи совсем маленьким, Алекс эмигрировал вместе с родителями из Украины. В поисках лучшей жизни они отправились в Канаду и поселились в маленьком городке в провинции Онтарио. Но оказалось, что начинать все заново в другой стране еще сложнее, чем они думали: даже когда мать Алекса наконец нашла работу, денег все время не хватало – все средства уходили на оплату счетов.
Алекс рос одиноким парнишкой: его лучшим другом стал мамин компьютер, с которым никогда не бывало скучно. Форумы, блоги, сайты с кучей полезной информации, игры – в Интернете было полно возможностей, и Алексу лишь нужно было отважиться ими воспользоваться. Сперва он решил использовать свои знания о Сети, чтобы заработать денег на учебу в колледже. Но затем его маму уволили, и банк, работы в котором она лишилась, стал угрожать, что отберет у них дом. Все это заставило Алекса вспомнить о DarkWeb – могущественной преступной организации, чьи кибератаки наводили ужас на государственную банковскую систему. Отомстить банкам мечтал и Алекс, однако он даже не представлял, в какую серьезную и опасную игру решил ввязаться.
Сперва он решил использовать свои знания о Сети, чтобы заработать денег на учебу в колледже. Но затем его маму уволили, и банк, работы в котором она лишилась, стал угрожать, что отберет у них дом. Все это заставило Алекса вспомнить о DarkWeb – могущественной преступной организации, чьи кибератаки наводили ужас на государственную банковскую систему. Отомстить банкам мечтал и Алекс, однако он даже не представлял, в какую серьезную и опасную игру решил ввязаться.
Фильм «Хакер» вы можете посмотреть онлайн на нашем сайте.
Приглашаем посмотреть фильм «Хакер» в нашем онлайн-кинотеатре совершенно бесплатно в хорошем HD качестве. Приятного просмотра!
Рейтинг Иви
Интересный сюжет
Рейтинг Иви
Интересный сюжет
Языки
Русский
Субтитры
Русский
Качество
Изображение и звук. Фактическое качество зависит от устройства и ограничений правообладателя.
FullHD
Рэкетир 2
Химера
Суперагенты
Должник
Беглец (2019)
Решала. Нулевые
Нулевые
Инкассаторы
Часовщик
Миллиард
На районе
Жизнь и приключения Мишки Япончика
Запретная зона
Этика долга
Курортный туман
Ловушка (2013)
Неуловимые: Бангкок
Решала: Брат
Тайсон
БУМЕРАНГ
Психология преступления. Жажда счастья
Акан
Сатаев
Каллэн
МакОлифф
Лоррэйн
Николсон
Дэниэл
Эрик Голд
Клифтон
Коллинз мл.
Захари
Беннетт
Кристиан
Трулсен
Джеймс
Байрон
Дэррил
Флэтмэн
Аллисон
Прэтт
Трейлер (дублированный)
1 мин.
Трейлер (английский язык)
2 мин.
Леденящие душу триллеры
Криминальные драмы
Фильмы, основанные на реальных событиях
Фильмы в HD
Данилюки, семья иммигрантов, переехавших в Канаду из Украины, начинают испытывать трудности с деньгами, вынуждены жить на пособие и вскоре могут лишиться дома.
У Алекса Данилюка было мало друзей, и он проводил время в Интернете, зарабатывая деньги в качестве «кликера», генерирующего онлайн-трафик для получения дохода веб-сайтов, но эта работа была малооплачиваемой и однообразной.
В конце концов, герой уезжает из дома, чтобы жить в Торонто и учиться в университете. Чтобы заработать дополнительные деньги на жизнь, Алекс Данилюк начинает заниматься преступной деятельностью и кражей личных данных. С помощью Сая, уличного барыги, который вводит его в мир торговли на черном рынке, они начинают заниматься мошенничеством с кредитными картами. Алекс попадается на попытке навести хаос в Королевском банке Канады, но попадается. Он убеждает Кертиса, главу службы безопасности банка, заключить сделку и отпустить его.
Попытка навести хаос на финансовом рынке, привлекает к Алексу внимание Зеда – таинственного человека в маске, который является главой организации, известной как Darkweb, и целью номер один для ФБР.
Герой знакомится с Кирой, молодой девушкой-хакером. Алекс просит Киру присоединиться к нему и Саю. Они начинают печатать собственные кредитные карты и торговать биткоинами, и вместе добиваются большого успеха. Сай начинает подозревать Киру, а девушка тем временем предлагает Алексу переехать в Гонконг, бросив Сая. Кира заключает сделку с мафией, которая срывается из-за Сая. Это вынуждает Сая задуматься о переезде.
Кира заключает сделку с мафией, которая срывается из-за Сая. Это вынуждает Сая задуматься о переезде.
Все трое переезжают в Гонконг, чтобы избежать дальнейшего внимания со стороны мафии. В Гонконге не все идет по плану, и после драки в ночном клубе Алекс и Сай оказываются в тюрьме. Кира вносит залог, чтобы их выпустили. Сай крадет деньги, используя старую карту, которую Алекс просил его не использовать. Это заканчивается серьезной ссорой друзей. В итоге Алекс просит Сая уйти.
Алекс и Кира грабят банкоматы в Гонконге и получают 2,3 миллиона долларов, оставляя после каждой операции визитные карточки Darkweb. Кира хочет выйти из дела, но Алекс настаивает, что нужно продолжать. Зед связывается с ним, и Алекс договаривается о личной встрече. Они встречаются на старой фабрике и с удивлением обнаруживают Зеда в инвалидном кресле и с обезображенным лицом. Алекс и Кира соглашаются работать на Зеда, который объясняет им, что за ошибку их ждет суровое наказание.
Сай возвращается в Гонконг и связывается с Алексом из их отеля, но мафия добирается до отеля первой и убивает его. Алекс и Кира выполняют согласованный с Зедом план по обвалу фондового рынка. Снайперы стреляют в председателя Федеральной резервной системы, что приводит к панике и краху рынка. Позже выясняется, что убийство было инсценировано.
Алекс и Кира выполняют согласованный с Зедом план по обвалу фондового рынка. Снайперы стреляют в председателя Федеральной резервной системы, что приводит к панике и краху рынка. Позже выясняется, что убийство было инсценировано.
Алекса и Киру похищают и разлучают. Алекс приходит в сознание в заброшенном офисе. Герой садится на самолет до Бангкока, где он договаривался встретиться с Кирой, если что-то пойдет не так, но в условленном месте в назначенное время она не появляется. Алекс пытается позвонить родителям, но мама не успевает взять трубку. Он начинает разбираться в случившемся и, находясь в интернет-кафе, использует левую кредитную карту. Служащий вызывает полицию, и пока она едет герой узнает об аресте Зеда и смерти Киры. Полиция приезжает и арестовывает Алекса. Вскоре он попадает в тюрьму.
После двух лет заключения и попытки самоубийства Алекса, наконец, освобождают. У ворот тюрьмы его встречает Кира, которая объясняет, что заключила сделку с ФБР. Алекс был ей нужен, чтобы подобраться к Зеду. В финале фильма они вместе уезжают.
В финале фильма они вместе уезжают.
Откуда такие высокие оценки? Не смотрите.
Для начала, немного мыслей, которые навеял мне просмотр данного фильма:
1) Не только русские фильмы могут быть плохими.
2) Оценки на ИВИ ничего не значат.
3) Надежда, хоть и умирает последней, но в данном случае, лучше не ждать.
4) Если ты не смотрел хоро
6 марта 2021
Евгений Мартыненко
Хакер? Не, не слышал.
Главный герой такой же хакер, как Шварцнеггер балерина. История простого мошенничества с кредитками и сбытом краденного.
Сценаристу и режиссеру неплохо было бы хотя бы прочитать определение хакера в википедии.
Молодой парень сначала зарабатывал простым се
25 января 2019
Написать рецензию

Приложение доступно для скачивания на iOS, Android, SmartTV и приставках
Подключить устройства
YouTube и Википедия вырываются на первое место в рейтинге брендов. пятерку лидеров, показал опрос, проведенный в пятницу.
Люди проходят мимо входа в новый розничный магазин Apple на Пятой авеню в Нью-Йорке 18 мая 2006 года. Интернет-компания Google снова подняла Apple на первое место в мировом рейтинге брендов, в котором также дебютировали YouTube и Wikipedia. пять, опрос показал в пятницу. REUTERS/Брендан Макдермид
Ежегодный опрос онлайн-журнала о брендинге brandchannel.com часто приводит к противоречивым результатам, например, в 2004 году, когда арабская телекомпания Al Jazeera была названа пятым самым влиятельным брендом в мире.
В этом году 3625 специалистов по брендингу и студентов, принявших участие в голосовании, снова удивили, присудив начинающим фирмам звездный статус, когда их спросили: «Какой бренд оказал наибольшее влияние на нашу жизнь в 2006 году?».
Google, интернет-поисковик, расширившийся в региональном масштабе и перешедший на онлайн-рекламу, почту и блоги, второй год подряд занимает первое место, опередив Apple Inc., которая снова занимает второе место.
Что еще более удивительно, сайт обмена видео YouTube, который был куплен Google в октябре прошлого года, ворвался на третье место. Интернет-энциклопедия Википедия занимает четвертое место, оттеснив кофейного гиганта Starbucks на пятое место.
«Впечатляющий дебют этих новичков — YouTube на третьем месте и Википедия на четвертом — свидетельствует о более широкой тенденции — растущем влиянии онлайн-брендов, основанных на пользовательском контенте», — сказал в своем заявлении редактор Энтони Зумпано. .
Другими победителями среди новых брендов стали сайт онлайн-чата News Corp MySpace, дебютировавший на 15-м месте в рейтинге Северной Америки, и Al Jazeera, поднявшаяся на 19-е место. место в мире, запустив свой англоязычный канал в ноябре и после того, как он упал с пятого на 25-е место в 2005 году. -Cola Co’s Coke на первом месте.
место в мире, запустив свой англоязычный канал в ноябре и после того, как он упал с пятого на 25-е место в 2005 году. -Cola Co’s Coke на первом месте.
Он также не просит респондентов подумать, является ли влияние бренда положительным или отрицательным.
Brandchannel также разделил опрос по регионам, и в Северной Америке краткое изложение было похоже на глобальный результат, хотя и в другом порядке, с Apple на первом месте, за которым следуют YouTube, Google, Starbucks и Wikipedia.
Первые пять мест в европейском списке занимают доморощенные корпорации, а шведский мебельный гигант Ikea вытеснил Nokia с первого места и занял третье место. Skype занимает второе место, бренд быстрой моды Zara — четвертое, а Adidas — пятое.
Аналогичным образом, местные компании доминируют в опросе Азиатско-Тихоокеанского региона, где первые пять мест занимают Sony, Toyota, HSBC, Samsung и Honda. HSBC, занявший третье место, имеет азиатские корни, хотя штаб-квартира находится в Лондоне.
И в отличие от высокотехнологичных брендов, которые доминируют в глобальном опросе, два лучших в Латинской Америке — напитки для вечеринок Corona и Bacardi, а оператор мобильной связи Movistar — на третьем. Производитель сандалий Havaianas занимает четвертое место, а Bimbo, производитель хлеба номер три в мире, занимает пятое место.
Индекс TIOBE — TIOBE
Индекс TIOBE — TIOBE
Июнь Заголовок: Останется ли Python номером 1?
Python был лауреатом ежегодной премии индекса TIOBE 3 раза за последние 5 лет. Его популярность росла как сумасшедшая из-за роста в области наук о данных и искусственного интеллекта. Подъем начался где-то осенью 2017 года с доли 3% и закончился в конце прошлого года с долей 17%. В этом году Python не смог удержать этот постоянно высокий уровень в 17% и упал до 13%. Остальные 3 претендента на первое место, C, Java и C++, приближаются. Останется ли Python номером 1? Это зависит, я думаю, в основном от популярности ИИ. Если такие инструменты, как ChatGPT, останутся в центре внимания, это привлечет новых посетителей, и тогда Python определенно останется. Если нет, Python должен опасаться за свою первую позицию. Помимо этой битвы за первое место, мы видим два интересных новых языка, которые впервые в этом месяце входят в топ-50: X++ (язык, используемый Microsoft Dynamics) и Raku (форк/преемник Perl). — Пол Янсен Генеральный директор TIOBE Software
Если нет, Python должен опасаться за свою первую позицию. Помимо этой битвы за первое место, мы видим два интересных новых языка, которые впервые в этом месяце входят в топ-50: X++ (язык, используемый Microsoft Dynamics) и Raku (форк/преемник Perl). — Пол Янсен Генеральный директор TIOBE Software
Индекс сообщества программистов TIOBE — показатель популярности программирования.
языки. Индекс обновляется раз в месяц. Рейтинг основан на количестве
квалифицированные инженеры по всему миру, курсы и сторонние поставщики. Популярные поисковые системы, такие как
Google, Bing, Yahoo!, Wikipedia, Amazon, YouTube и Baidu используются для расчета рейтингов.
Важно отметить, что индекс TIOBE не относится к лучшим языкам программирования из или языку
в котором написано больше всего строк кода .
Индекс можно использовать для проверки актуальности ваших навыков программирования или для создания
стратегическое решение о том, какой язык программирования следует использовать при создании нового
программная система..jpg) Определение индекса TIOBE можно найти здесь.
Определение индекса TIOBE можно найти здесь.
| июнь 2023 г. | июнь 2022 г. | Изменить | Язык программирования | Рейтинги | Изменить | |
|---|---|---|---|---|---|---|
| 1 | 1 | Python | 12,46% | +0,26% | ||
| 2 | 2 | C | 12,37% | +0,46% | ||
| 3 | 4 | C++ | 11,36% | +1,73% | ||
| 4 | 3 | Ява | 11,28% | +0,81% | ||
| 5 | 5 | C# | 6,71% | +0,59% | ||
| 6 | 6 | Visual Basic | 3,34% | -2,08% | ||
| 7 | 7 | JavaScript | 2,82% | +0,73% | 8 | 13 | PHP | 1,74% | +0,49% |
| 9 | 8 | SQL | 1,47% | -0,4 7% | ||
| 10 | 9 | Ассемблер | 1,29% | -0,56% | ||
| 11 | 12 | Delphi/Object Pascal | 1,26% | -0,07% | ||
| 12 | 24 | MATLAB | 1,11% | +0,48% | ||
| 13 | 25 | 900 70 | Царапина | 1,02% | +0,43% | |
| 14 | 15 | 1,00% | -0,02% | |||
| 15 | 26 | Фортран 900 70 | 0,99% | +0,44% | ||
| 16 | 11 | Классический Visual Basic | 0,96% | -0,36% | ||
| 17 | 16 | Р | 0,94% | -0,04% | ||
| 18 | 19 | Рубин | 0,94% | +0,19% | ||
| 19 | 10 | Свифт | 0,93% | -0,62% | ||
| 20 | 27 | Ржавчина | 0,91% | +0,38% | ||
Другие языки программирования
Полный список 50 лучших языков программирования приведен ниже. Этот обзор
Этот обзор
опубликовано неофициально, потому что может случиться так, что мы пропустили язык. Если
у вас сложилось впечатление, что не хватает языка программирования, пожалуйста, сообщите нам
на [email protected]. Пожалуйста, также проверьте обзор всех языков программирования, которые мы отслеживаем.
| Позиция | Язык программирования | Рейтинги |
|---|---|---|
| 21 | (Visual) FoxPro | |
| 22 | COBOL | 0,75% |
| 23 | SAS | 0,72% |
| 24 | Objective-C | 0,65% |
| 25 | Perl | |
| 26 | Ада | 0,61% |
| 27 | Юлия | 0,60% |
| 28 | Д | 0,55% |
| 29 | Котлин | 0,52% |
| 30 | Сделка -SQL | 0,51% |
| 31 | Haskell | 0,49% |
| 32 | Lua | 0,47% |
| 33 | Лисп | 0,44% |
| 34 | Дротик | 0,42% |
| 35 | Scala | 0,39% 900 70 |
| 36 | Prolog | 0,35% |
| 37 | PL/SQL | 0,34% |
| 38 | Логотип | 0,31% |
| 39 | Схема | 0,30% 9007 0 |
| 40 | VBScript | 0,28% |
| 41 | F# | 0. 26% 26% |
| 42 | ABAP | 0.26% |
| 43 | X++ | 0.26% |
| 44 | TypeScript | 0.25% |
| 45 | CFML | 0,25% |
| 46 | Awk | 0,24% |
| 47 9 0070 | МЛ | 0,22% |
| 48 | Раку | 0,22% |
| 49 | Форт | 0,22% |
| 50 | Апекс |
Следующие 50 языков программирования
Следующий список языков обозначает языки с #51 по #100. Так как различия
относительно небольшой, языки программирования только перечислены (в алфавитном порядке).
заказ).
- 4-е измерение/4D, ABC, ActionScript, Algol, Alice, APL, Bash, bc, Boo, Bourne shell, Caml, Carbon, CL (OS/400), CLIPS, Clojure, CoffeeScript, Crystal, Elixir, Erlang, Euphoria, GAMS , Groovy, Hack, Icon, Io, J, J#, JScript, LabVIEW, Ladder Logic, LiveCode, Maple, NATURAL, Nim, OCaml, Oz, PL/I, PostScript, PowerShell, Q, Racket, Ring, RPG, Smalltalk, Solidity, SPARK, Tcl, VHDL, Wolfram, X10
Изменения индекса в этом месяце
В этом месяце в определение индекса внесены следующие изменения:
Очень долгая история
Чтобы увидеть более широкую картину, пожалуйста, ознакомьтесь с позициями 10 лучших языков программирования многолетней давности. Обратите внимание, что это в среднем позиций за период 12 месяцев.
Обратите внимание, что это в среднем позиций за период 12 месяцев.
| Язык программирования | 2023 | 2018 | 2013 | 2008 | 2003 | 1993 | 1988 | |
|---|---|---|---|---|---|---|---|---|
| Python | 1 | 4 | 8 | 12 | 25 | 19 | — | |
| C | 2 | 2 | 1 | 2 | 2 | 1 | 1 | 1 |
| Ява | 3 | 1 | 2 | 1 | 1 | 18 | — | — |
| C++ | 4 | 3 | 4 | 4 | 3 | 2 | 2 | 5 |
| 5 | 5 | 5 | 8 | 9 | — | — | — | |
| Visual Basic | 6 | 15 | — | — | — | — | — | — |
| JavaScript | 7 | 7 | 11 | 9 | 8 | 21 | — | — |
| SQL | 8 | 251 | — | 7 | — | — | — | |
| Ассемблер | 9 | 13 | — | — | — | — | — | — 9 0070 |
| PHP | 10 | 8 | 6 | 5 | 6 | — | — | — |
| Объектив-C | 19 | 17 | 3 | 44 | — | — | — | |
| Ада | 25 | 28 | 18 | 19 | 15 | 9 | 6 | 3 |
| Lisp | 29 | 31 | 12 | 16 | 14 | 8 | 5 | 2 |
| Паскаль | 189 | 147 | 15 | 18 | 99 | 3 | 14 | |
| (визуальный) Базовый | — | — | 7 | 3 | 5 | 3 | 8 | 6 |
Здесь есть 2 важных замечания. :
:
- В таблице выше есть разница между «Visual Basic» и «(Visual) Basic». До 2010 года «(Visual) Basic» относился ко всем возможным диалектам Basic, включая Visual Basic. После некоторого обсуждения было решено разделить «(Visual) Basic» на все его диалекты, такие как Visual Basic .NET, Classic Visual Basic, PureBasic и Small Basic, и это лишь некоторые из них. Поскольку Visual Basic .NET стал основной реализацией Visual Basic, теперь он называется «Visual Basic».
- Язык программирования SQL был добавлен в индекс TIOBE в 2018 году после того, как кто-то указал, что SQL является завершенным по Тьюрингу. Таким образом, хотя этот язык очень старый, в указателе он имеет лишь короткую историю.
Зал славы языков программирования
Зал славы, в котором перечислены все лауреаты премии «Язык программирования года», показан ниже. Награда присуждается языку программирования, у которого самый высокий рост рейтинга за год.
| Год | Победитель |
|---|---|
| 2022 | C++ |
| 2021 | Python |
| 2020 | Python |
| 2019 | C |
| 2018 90 070 | Питон |
| 2017 | C |
| 2016 | Go |
| 2015 | Java 9 0070 |
| 2014 | JavaScript |
| 2013 | Transact-SQL |
| 2012 | Objective-C |
| 20 11 | Objective-C |
| 2010 | Python |
| 2009 | Go |
| 2008 | C |
| 2007 | Питон |
| 2006 | Рубин |
| 2005 | Ява |
| 2004 | PHP |
| 2003 | C++ |
Ошибки и запросы на изменение
9 0002 Это топ-5 наиболее востребованных изменений и ошибок. Если у вас есть предложения по улучшению индекса, не стесняйтесь присылать их по адресу [email protected].
Если у вас есть предложения по улучшению индекса, не стесняйтесь присылать их по адресу [email protected].
- Помимо «программирования на <языке>», следует опробовать и другие запросы, такие как «программирование на <языке>», «разработка на <языке>» и «кодирование на <языке>».
- Добавить запросы для других естественных языков (кроме английского). Идея состоит в том, чтобы начать с китайской поисковой системы Baidu. Это было реализовано частично и будет завершено в ближайшие несколько месяцев.
- Добавить список всех запросов поисковых запросов, которые были отклонены. Это сделано для того, чтобы свести к минимуму количество повторяющихся писем о Rails, JQuery, JSP и т. д.
- Запустите индекс TIOBE для баз данных, систем управления конфигурацией программного обеспечения и сред приложений.
- Некоторые поисковые системы позволяют запрашивать страницы, которые были добавлены в прошлом году. Индекс TIOBE должен отслеживать только те недавно добавленные страницы.
Да, единственным условием является ссылка на первоисточник «www.tiobe.com».
Если язык соответствует критериям включения в список (т. е. он завершен по Тьюрингу и имеет собственную запись в Википедии, указывающую, что он относится к языку программирования) и достаточно популярен (более 5000 просмотров для +»<язык> программирование» для Google), напишите письмо по адресу [email protected].
Мы потратили много усилий, чтобы получить все данные и поддерживать индекс TIOBE в актуальном состоянии. Чтобы немного компенсировать это, мы просим плату в размере 5000 долларов США за полный набор данных. Набор данных работает с июня 2001 года по сегодняшний день. Он начался с 25 языков еще в 2001 году, а теперь измеряет более 150 языков один раз в месяц. Данные доступны в формате, разделенном запятыми. Пожалуйста, свяжитесь с [email protected] для получения дополнительной информации.
Ну, вы можете сделать это любым способом, и оба варианта неверны. Если вы возьмете сумму, то вы получите пересечение дважды.
Leave a Reply