Как правильно транслитерировать (ИКАО, ГОСТ Р 52535.1-2006, ISO 9, BSI)
Казалось бы, что может быть проще: транслитерировать имя или адрес с одного языка на другой.
Но, как и в любом деле, все сложнее, чем кажется. Если заглянуть в Википедию, отыщется не меньше пяти разных способов транслитерации. Это неудивительно: у разных учреждений бывают разные требования, а имена и адреса часто транслитерируются как придется.
Единого стандарта для перевода кириллицы в латиницу пока не существует. Поэтому мы обычно просим клиентов выслать нам написание имен, если им уже приходилось переводить соответствующие документы, или указывать имя и адрес, например, при подаче заявки. Так можно избежать ненужных расхождений в текстах.
Стандарты ФМС
При передаче кириллицы на латиницу ФМС ориентируется на способ, принятый ИКАО (Международной организацией гражданской авиации). Раньше ФМС применяла ГОСТ Р 52535.1-2006 (2010–2012). В некоторых паспортах все еще используется транслитерация по этому ГОСТу.
По умолчанию мы, как и ФМС, транслитерируем имена по способу ИКАО и дополнительно запрашиваем данные у клиента.
На внутренней странице задней части обложки (задний форзац) в реквизите «Фамилия» указывается фамилия заявителя: в первой строке — на русском языке и через знак «/» во второй строке — способом транслитерации (простого замещения русских букв на латинские) в соответствии с рекомендованным ИКАО международным стандартом (Doc 9303, часть 1).
фрагмент приказа ФМС от 26 марта 2014 г. № 211
Транслитерация библиографических списков
Какую систему транслитерации выбрать для списков литературы на русском языке? Зависит от издательства, которое будет публиковать работу.
Самые популярные стандарты — BSI (British Standard Institute (UK) & ISI — Institute for Scientific Information (USA)), BGN/BGCN (The United States Board on Geographic Names) и ALA-LC (American Library Association (ALA) and the Library of Congress (LC)). О том, какой стандарт транслитерации нужен именно вам, можно узнать в требованиях к публикации вашего издательства.
О том, какой стандарт транслитерации нужен именно вам, можно узнать в требованиях к публикации вашего издательства.
При необходимости мы можем помочь вам транслитерировать или перевести библиографический список. Главное для вас — сообщить нам, какие требования соблюдать.
Стандарт ISO 9
ISO 9 — стандарт транслитерации кириллических имен собственных по принципу «одна буква на кириллице соответствует одной букве на латинице». Согласно этому стандарту транслитерируются ФИО, а также географические названия, если для них еще нет устоявшегося перевода (в словаре Duden).
Иногда нас просят сделать транслитерацию по ISO 9 для Германии. При транслитерации по стандарту ISO 9 мы в скобках также указываем перевод имени по заграничному паспорту.
Как же все-таки правильно?
Стандарт не означает закон. Единственно правильного варианта транслитерации не существует, поэтому все зависит от конкретной ситуации. Просто выберите способ транслитерации, который вам подходит, и сообщите нам.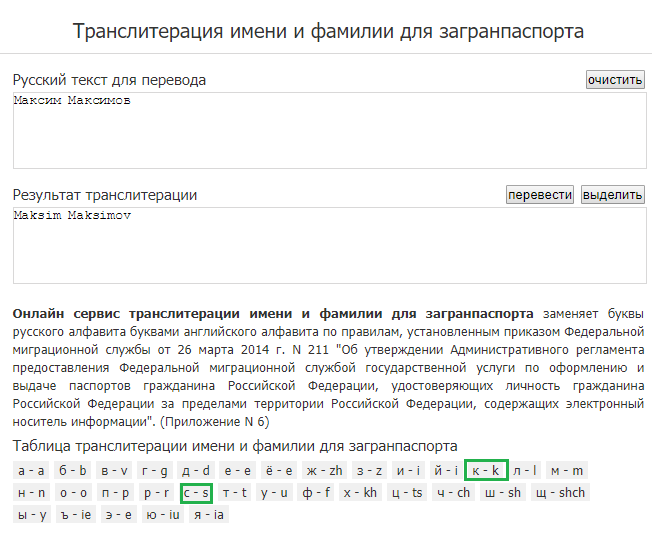
Самые распространенные стандарты транслитерации
| Кириллица | ИКАО | ГОСТ Р 52535.1-2006 | Стандарт ISO 9 | Стандарт BSI |
|---|---|---|---|---|
| А | A | A | A | A |
| Б | B | B | B | B |
| В | V | V | V | V |
| Г | G | G | G | G |
| Д | D | D | D | D |
| Е | E | E | E | E |
| Ё | E | E | Ё | E |
| Ж | ZH | ZH | Z̄ | ZH |
| З | Z | Z | Z | Z |
| И | I | I | I | I |
| Й | I | I | Ī | I |
| К | K | K | K | K |
| Л | L | L | L | L |
| М | M | M | M | M |
| Н | N | N | N | N |
| О | O | O | O | O |
| П | P | P | P | P |
| Р | R | R | R | R |
| С | S | S | S | S |
| Т | T | T | T | T |
| У | U | U | U | U |
| Ф | F | F | F | F |
| Х | KH | KH | H | KH |
| Ц | TS | TC | C | TS |
| Ч | CH | CH | Č | CH |
| Ш | SH | SH | Š | SH |
| Щ | SHCH | SHCH | Ŝ | SHCH |
| Ь | ʹ | ʹ | ||
| Ы | Y | Y | Y | Y |
| Ъ | IE | ʺ | ʺ | |
| Э | E | E | È | E |
| Ю | IU | IU | Û | YU |
| Я | IA | IA | Â | YA |
Будем рады ответить на вопросы и просто подискутировать на тему транслитерации в комментариях.![]()
Транслитерация ГОСТ 16876-71
Стандарт распространяется на транслитерацию букв кирилловского алфавита буквами латинского алфавита в области научной и технической информации и устанавливает соответствие между буквами кирилловского алфавита, употребляемыми в русском, украинском, белорусском, болгарском, македонском, сербскохорватском (в его кирилловском письменном варианте) и монгольском языках, и буквами латинского алфавита. Здесь приводится транслитерация только русского алфавита. При обмене информацией на машиночитаемых носителях применение данного способа транслитерации обязательно.
Дата введения: 07.01.73
Дата отмены: 07.01.2002
Заменен на: ГОСТ 7.79-2000
Таблица транслитерации с использованием диакритических знаков
| а | a |
| б | b |
| в | v |
| г | g |
| д | d |
| е | e (je) |
| ё | ё |
| ж | ž |
| з | z |
| и | i |
| й | j |
| к | k |
| л | l |
| м | m |
| н | n |
| о | o |
| п | p |
| р | r |
| с | s |
| т | t |
| у | u |
| ф | f |
| х | h (ch) |
| ц | c |
| ч | č |
| ш | š |
| щ | ŝ (šč) |
| ъ | « |
| ы | y |
| ь | ‘ |
| э | è |
| ю | û (ju) |
| я | â (ja) |
Таблица транслитерации с использованием только сочетаний латинских букв
| а | a |
| б | b |
| в | v |
| г | g |
| д | d |
| е | e |
| ё | jo |
| ж | zh |
| з | z |
| и | i |
| й | jj |
| к | k |
| л | l |
| м | m |
| н | n |
| о | o |
| п | p |
| р | r |
| с | s |
| т | t |
| у | u |
| ф | f |
| х | kh |
| ц | c |
| ч | ch |
| ш | sh |
| щ | shh |
| ъ | « |
| ы | y |
| ь | ‘ |
| э | eh |
| ю | ju |
| я | ja |
Источник:
— ГОСТ 16876-71 Правила транслитерации букв кирилловского алфавита буквами латинского алфавита.![]() Переиздание январь 1981 г. с изменениями 1 и 2, утвержденными в декабре 1973 г. и в марте 1980 г.,
Переиздание январь 1981 г. с изменениями 1 и 2, утвержденными в декабре 1973 г. и в марте 1980 г.,
— М.: Издательство стандартов, 1981.
Unicode CLDR — Рекомендации по транслитерации Unicode
В этом документе описаны рекомендации по созданию и использованию транслитераций CLDR. Предварительные диаграммы доступны для доступных транслитераций — обязательно прочтите там известные проблемы. Пожалуйста, отправляйте любые отзывы об этом документе или этих диаграммах по адресу Locale Bugs .
Транслитерация — это общий процесс преобразования символов из одного алфавита в другой, при котором результат является примерно фонетическим для языков в целевом алфавите. Например, «Фобос» и «Деймос» — это транслитерация греческих мифологических «Φόβος» и «Δεῖμος» латинскими буквами, которые используются для обозначения спутников Марса.
Транслитерация — это , а не перевод. Скорее, транслитерация — это преобразование букв из одного алфавита в другой без перевода основных слов. Ниже приведены примеры систем транслитерации:
Скорее, транслитерация — это преобразование букв из одного алфавита в другой без перевода основных слов. Ниже приведены примеры систем транслитерации:
Дисплей. Некоторые символы в этом документе могут быть не видны в вашем браузере, а в некоторых шрифтах диакритические знаки не будут правильно размещены на основных буквах. См. Проблемы с дисплеем .
В то время как англоговорящий человек может не распознать, что японское слово kyanpasu эквивалентно английскому слову campus , слово kyanpasu все же намного легче распознать и интерпретировать, чем если бы буквы были оставлены в исходном письме. . Есть несколько ситуаций, когда эта транслитерация особенно полезна, например следующая. Примеры смотрите на боковой панели.
Термину транслитерации иногда придают узкое значение, подразумевая, что трансформация обратимый (иногда называемый без потерь ). В CLDR это не так; термин транслитерация интерпретируется широко и означает как обратимые, так и необратимые преобразования текста. (Обратите внимание, что даже если теоретически предполагается, что система транслитерации является обратимой, в исходных стандартах она часто не указывается достаточно подробно в крайних случаях, чтобы быть действительно обратимой.) Необратимая транслитерация часто называется транскрипцией , или называется с потерями или неоднозначная транскрипция.
В CLDR это не так; термин транслитерация интерпретируется широко и означает как обратимые, так и необратимые преобразования текста. (Обратите внимание, что даже если теоретически предполагается, что система транслитерации является обратимой, в исходных стандартах она часто не указывается достаточно подробно в крайних случаях, чтобы быть действительно обратимой.) Необратимая транслитерация часто называется транскрипцией , или называется с потерями или неоднозначная транскрипция.
Обратите внимание, что обратимость, как правило, только в одном направлении, поэтому транслитерация с родного письма на латиницу может быть обратимой, но не наоборот. Например, хангыль является обратимым в том смысле, что любой хангыль на латыни и хангыль должен обеспечивать тот же хангыль, что и ввод. Таким образом, мы имеем следующее:
갗 → gach → 갗
Однако для полноты картины многие латинские символы имеют запасные варианты. Это означает, что один и тот же хангыль может сопоставляться более чем одному латинскому символу. Таким образом из Latin у нас нет обратимости, потому что две разные исходные латинские строки возвращаются к одной и той же латинской строке.
Это означает, что один и тот же хангыль может сопоставляться более чем одному латинскому символу. Таким образом из Latin у нас нет обратимости, потому что две разные исходные латинские строки возвращаются к одной и той же латинской строке.
gach → 갗 → gach
gac → 갗 → gach
Транслитерация также может использоваться для преобразования незнакомых букв в одном и том же алфавите, например, для преобразования исландского THORN (þ) в th. Обычно они необратимы.
Существует онлайн-демонстрация с использованием опубликованных данных CLDR по адресу ICU Transform Demo .
Варианты
Существует множество систем транслитерации между языками: один и тот же текст можно транслитерировать разными способами. Например, для греческого примера выше транслитерация является классической, в то время как альтернатива UNGEGN имеет другие соответствия, такие как φ → f вместо φ → ph .
CLDR обеспечивает общие сопоставления одного сценария с другим (например, кириллица-латиница), а также варианты для конкретных языков (русский-французский или сербский-немецкий). Также могут быть полуобщие отображения, такие как русский-латиница или кириллица-французский. Их можно назвать, соответственно, транслитерацией сценария, транслитерацией для конкретного языка или транслитерацией языка сценария. Транслитерации с других письменностей на латиницу также называются Романизация .
Даже в пределах отдельных языков могут быть варианты систем в зависимости от разных органов или даже меняющиеся во времени (если орган власти для системы меняет свои рекомендации). Канонический идентификатор, который CLDR использует для них, имеет следующий вид:
исходный-цель/вариант
Исходным (и целевым) может быть язык или скрипт, использующий либо английское имя, либо код локали. Вариант должен указывать полномочия для системы и, если необходимо для устранения неоднозначности, год. Например, идентификатор транслитерации с русского на латиницу по системе UNGEGN будет следующим:
Например, идентификатор транслитерации с русского на латиницу по системе UNGEGN будет следующим:
Если бы с течением времени существовало несколько их версий, вариант был бы, скажем, UNGEGN2006.
Предполагается, что реализации позволяют использовать запасные варианты, если указанная точная транслитерация недоступна. Например, ниже будет резервная цепочка для идентификатора русский-английский/UNGEGN. Это похоже на резервный шаблон поиска , используемый в тегах BCP 47 для идентификации языков, за исключением того, что он использует «ступенчатый подход» для постепенной обработки резервного варианта между источником, целью и вариантом с приоритетами: цель, источник и вариант именно в таком порядке.
Инструкции
Существует ряд общепринятых рекомендаций по транслитерации скриптов. Эти рекомендации редко выполняются одновременно, поэтому построение разумной транслитерации всегда представляет собой процесс уравновешивания различных требований. Эти требования наиболее важны для людей, занимающихся транслитерацией, но также полезны в качестве справочной информации для пользователей.
Эти требования наиболее важны для людей, занимающихся транслитерацией, но также полезны в качестве справочной информации для пользователей.
Ниже перечислены общие рекомендации по транслитерации Unicode CLDR:
стандарт: следовать установленным системам (стандарты, органы или де-факто практика), где это возможно, иногда отклоняясь там, где это необходимо для обеспечения обратимости. В CLDR системы обычно описываются в комментариях к файлам данных XML, которые можно найти в онлайн-папке transforms. Например, система арабской транслитерации в CLDR находится в комментариях в Arabic-Latin.xml; есть ссылка на арабские таблицы UNGEGN. То же самое и для иврита, который также соответствует таблицам UNGEGN для иврита.
завершено : каждая правильно сформированная последовательность символов в исходном сценарии должна транслитерироваться в последовательность символов из целевого сценария и наоборот.

предсказуемый : самих букв (без знания языков, написанных этим шрифтом) должно быть достаточно для транслитерации на основе относительно небольшого количества правил. Это позволяет выполнять транслитерацию механически.
произносимый : полученные символы имеют разумное произношение в целевом сценарии. Транслитерация не так полезна, если процесс просто отображает символы без учета их произношения. Простое сопоставление в алфавитном порядке («αβγδεζηθ…» в «abcdefgh…») может дать строки, которые могут быть полными и недвусмысленными, но произношение будет совершенно неожиданным.
обратимый : можно восстановить текст в исходном письме из транслитерации в целевом письме. То есть тот, кто знает правила транслитерации, сможет восстановить точное написание исходного текста. Например, можно перейти с Elláda вернуться к исходному Ελλάδα, а если бы транслитерация была Ellada (без акцента), это было бы невозможно.

Некоторые из этих принципов могут быть недостижимы одновременно; в частности, соблюдение стандартной системы и обратимости . Часто небольшие изменения в существующих системах могут быть сделаны для обеспечения обратимости. Однако, если в конкретной системе указаны принципиально необратимые транслитерации, те транслитерации, представленные в CLDR, могут быть необратимыми.
Неоднозначность
При транслитерации несколько символов могут вызывать неоднозначность (необратимое сопоставление), если правила не разработаны тщательно. Например, греческий символ PSI (ψ) отображается в пс , но пс также может быть результатом последовательности PI, SIGMA (πσ), поскольку PI (π) отображается в p, а SIGMA (σ) отображается в s.
Японские стандарты транслитерации обеспечивают хороший механизм для обработки такого рода двусмысленностей.![]() При использовании японских стандартов транслитерации всякий раз, когда неоднозначная последовательность в целевом сценарии не является результатом одной буквы, преобразование использует апостроф для устранения неоднозначности. Например, эта процедура используется для различения манити и манити . С помощью этой процедуры греческий символ PI SIGMA (πσ) преобразуется в p . Этот метод рекомендуется для всех методов транслитерации алфавита, хотя иногда символ может отличаться: например, в корейском языке используется «-».
При использовании японских стандартов транслитерации всякий раз, когда неоднозначная последовательность в целевом сценарии не является результатом одной буквы, преобразование использует апостроф для устранения неоднозначности. Например, эта процедура используется для различения манити и манити . С помощью этой процедуры греческий символ PI SIGMA (πσ) преобразуется в p . Этот метод рекомендуется для всех методов транслитерации алфавита, хотя иногда символ может отличаться: например, в корейском языке используется «-».
Примечание: Недавно у нас было предложение последовательно использовать точку для дефиса для этого кода, таким образом, мы получили бы πσ → p‧s.
Вторая проблема заключается в том, что некоторые символы в целевом скрипте обычно не встречаются вне определенных контекстов. Например, маленький японский иероглиф «я», как и в «кья» (キャ), обычно не встречается изолированно. Для обработки таких символов транслитерация Unicode в настоящее время использует другие соглашения.
Примечание: Комитет CLDR рассматривает возможность согласования этого общего представления. Преимущество общего представления в том, что оно позволяет легко фильтровать.
Для преобразований сценария по умолчанию цель состоит в том, чтобы иметь однозначные сопоставления с вариантами для любых общеупотребительных сопоставлений, которые являются неоднозначными (необратимыми). Однако в некоторых случаях регистр может не сохраняться. Например,
Ниже показан греческий текст, преобразованный в полностью обратимую латиницу:
Греко-латинский
τί φῄς; γραφὴν σέ τις, ὡς ἔοικε, γέγραπται: οὐ γὰρ ἐκεῖνό γε καταγνώσομαι, ὡς σὺ ἕτερον.
ти фиис; graphḕn sé tis, hōs éoike, gégraptai: ou gàr ekeînó ge katagnṓsomai, hōs sỳ héteron.
Если пользователю нужна версия без определенных акцентов, то можно использовать правила цепочки CLDR для удаления акцентов. Например, следующий текст транслитерируется на латынь, но удаляет макронные акценты на долгих гласных.
Например, следующий текст транслитерируется на латынь, но удаляет макронные акценты на долгих гласных.
греко-латынь; нфд; [\u0304] удалить; nfc
τί φῄς; γραφὴν σέ τις, ὡς ἔοικε, γέγραπται: οὐ γὰρ ἐκεῖνό γε καταγνώσομαι, ὡς σὺ ἕτερον.
ті фейс; graphèn sé tis, hos éoike, gégraptai: ou gàr ekeînó ge katagnósomai, hos sỳ héteron.
Приведенные выше правила объединения в цепочки, разделенные точкой с запятой, выполняют следующие команды по порядку:
Следующие команды транслитерируются на латиницу, но удаляются все акцента. Обратите внимание, что единственное изменение заключается в расширении фильтра для удалить команду .
греко-латынь; нфд; [:без пробелов:] удалить; nfc
τί φῄς; γραφὴν σέ τις, ὡς ἔοικε, γέγραπται: οὐ γὰρ ἐκεῖνό γε καταγνώσομαι, ὡς σὺ ἕτερον.
тифейс; graphen set tis, hos eoike, gegraptai: ou gar ekeino ge katagnosomai, hos sy heteron.
Произношение
Стандартные методы транслитерации часто не следуют правилам произношения какого-либо конкретного языка в целевом сценарии. Например, в японской системе Хепберна используется буква «j», которая имеет английское фонетическое значение (в отличие от французского, немецкого или испанского), но использует гласные, которые не имеют стандартных английских звуков. Метод транслитерации также может потребовать некоторых специальных знаний для правильного произношения. Например, в японской системе кунрей-сики «ти» произносится как английское «чи».
Это похоже на ситуации, когда в одном сценарии используются разные языки. Например, знание того, что слово Gewalt происходит из немецкого языка, позволяет знающему читателю произносить «w» как «v». При встрече с таким иностранным словом, как джава , мало уверенности в том, как его произносить, даже если это не транслитерация (это просто слово из /span>другого языка с латинским шрифтом). j может произноситься (для говорящего по-английски) как jump , или Junker , или jour ; и так далее. Транскрипции только грубо фонетические, и только тогда, когда понятны конкретные правила произношения.
j может произноситься (для говорящего по-английски) как jump , или Junker , или jour ; и так далее. Транскрипции только грубо фонетические, и только тогда, когда понятны конкретные правила произношения.
На произношение символов в оригинальном письме также может влиять контекст, который может вводить в заблуждение при транслитерации. Ибо в бенгальском языке নিঃশব, транслитерируемом как niḥśaba, Visarga ḥ не произносится само по себе (в то время как в других местах это может быть), но удлиняет 9Звук 0003 ś , а конечная присущая a произносится (в то время как обычно нет), а два неотъемлемых a произносятся как ɔ и ô соответственно.
В некоторых случаях на транслитерацию могут сильно влиять традиции. Например, современная греческая буква бета (β) звучит как «v», но транслитерация может использовать b (как в биология ). В этом случае пользователю необходимо знать, что буква «b» в транслитерированном слове соответствует бета (β) и должна произноситься как 9.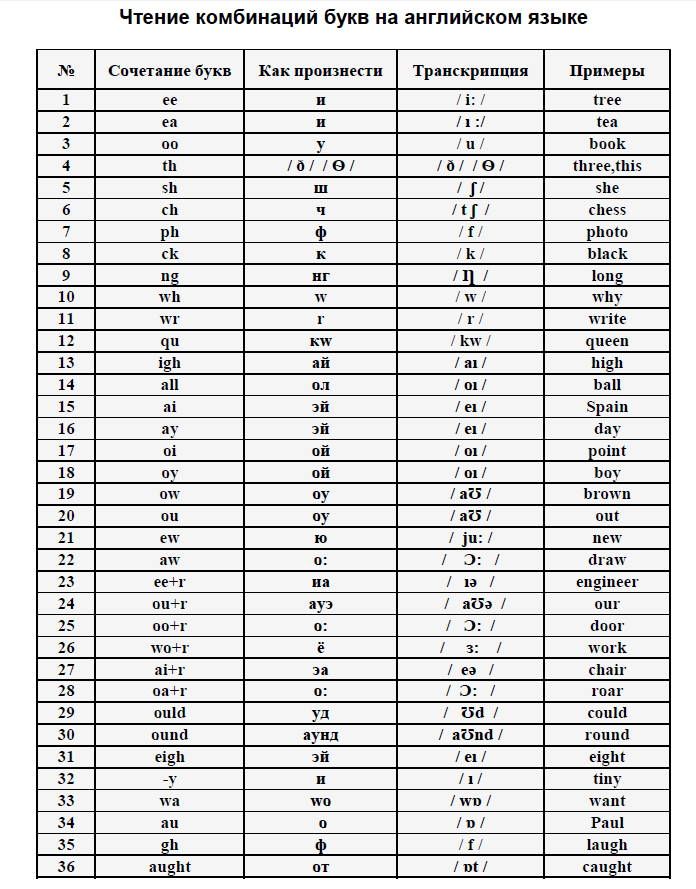 0003 v в новогреческом.
0003 v в новогреческом.
Буквы также могут транслитерироваться по-разному в зависимости от их контекста, чтобы сделать произношение более предсказуемым. Например, поскольку греческая последовательность ГАММА ГАММА (γγ) произносится как нг , первая ГАММА может быть транскрибирована как «n» в этом контексте. Точно так же транслитерация может дать другое руководство по произношению на исходном языке, например, использование «n» или «m» для одного и того же японского символа (ん) в зависимости от контекста, даже если в исходном письме нет различия.
В общем, предсказуемость означает, что при транслитерации латинского алфавита в другие алфавиты с использованием обратимой транслитерации английский текст не даст фонетических результатов. Это связано с тем, что произношение английского языка нельзя легко предсказать по буквам в слове: например, grove , move и love заканчиваются на «ove», но произносятся по-разному.
Меры предосторожности
Обратимость может потребовать модификации традиционных методов транскрипции. Например, есть два стандартных метода транслитерации японских катаканы и хираганы латинскими буквами. kunrei-siki метод однозначен. Метод Хепберна легче произносится иностранцами, но он неоднозначен. В методе Хепберна как ZI (ジ), так и DI (ヂ) представлены как «ji», а ZU (ズ) и DU (ヅ) представлены как «zu». Слегка измененная версия Хепберн, в которой используется «дзи» для DI и «дзу» для DU, недвусмысленна.
Когда последовательность из двух букв сопоставляется с одной, сопоставление регистра (верхний и нижний регистр) должно выполняться осторожно, чтобы обеспечить обратимость. Для сценариев с регистром две буквы могут иметь разные регистры, в зависимости от следующей буквы. Например, греческая буква PHI (Φ) соответствует PH на латыни, но Φο соответствует Pho, а не PHo.
В некоторых сценариях есть символы, которые принимают разные формы в зависимости от их контекста. Обычно это делается на уровне отображения (например, с арабским языком) и не требует специальной поддержки транслитерации. Однако в некоторых случаях это представлено разными кодами символов, например, в греческом и иврите. Например, греческая SIGMA пишется в конечной форме (ς) в конце слов и в неконечной форме (σ) в других местах. Это также требует, чтобы преобразование отображало разные символы в зависимости от контекста.
Обычно это делается на уровне отображения (например, с арабским языком) и не требует специальной поддержки транслитерации. Однако в некоторых случаях это представлено разными кодами символов, например, в греческом и иврите. Например, греческая SIGMA пишется в конечной форме (ς) в конце слов и в неконечной форме (σ) в других местах. Это также требует, чтобы преобразование отображало разные символы в зависимости от контекста.
Еще одна вещь, на которую следует обратить внимание при работе с алфавитами с регистром, заключается в том, что некоторые символы в целевом алфавите могут не представлять различий между регистрами, например, некоторые символы IPA в латинице.
Полезно, чтобы обратное сопоставление было полным, чтобы произвольные строки в целевом скрипте могли быть обоснованно сопоставлены обратно с исходным скриптом. Полное обратное отображение значительно упрощает проверку механического качества и т.д. Например, даже если буква «q» может не понадобиться в транслитерации греческого языка, ее можно сопоставить с KAPPA (κ). Такие обратные отображения, вообще говоря, не будут однозначными.
Такие обратные отображения, вообще говоря, не будут однозначными.
Доступные транслитерации
В настоящее время Unicode CLDR предлагает романизацию для определенных шрифтов, а также транслитерацию между индийскими шрифтами (за исключением урду). Дополнительные транслитерации сценария будут добавлены в будущем.
Если не указано иное, все эти системы спроектированы так, чтобы быть обратимыми. Однако для двухкамерных шрифтов (с прописными и строчными буквами) регистр может сохраняться не полностью.
Транслитерация также разработана так, чтобы быть полной для любой последовательности латинских букв а-я . Запасной вариант используется для буквы, которая не охватывается транслитерацией, и буквы по умолчанию могут быть вставлены по мере необходимости. Например, в транслитерации хангыль rink → 린크 → linkeu . То есть «r» сопоставляется с ближайшей другой буквой, а в конце вставляется гласная по умолчанию (поскольку «nk» не может заканчивать слог).
Предварительная таблицы доступны для доступных транслитераций. Обязательно прочитайте известные проблемы, описанные там.
Корейский
Существует множество романизаций корейского языка. Транслитерация по умолчанию в Unicode CLDR соответствует правилам транслитерации Министерства культуры и туризма Кореи (см. также сводку на английском языке). Существует необязательная пункт 8 Вариант для обратимости:
«제 8 항 연구 논문 등 특수 분야 에서 한글 복원 전제 로 표기 경우 에는 특수 분야 에서 으로 적는다. 이때 대응 대응 제 2 장 따르되 , ㄷ, ㅂ, ㄹ ‘은’ G, D, B, L ‘로 만 적는다. (-)를 쓴다».
перевод: «Статья 8: Когда требуется точно восстановить исходное представление хангыль, как в научных статьях, «ㄱ, ㄷ, ㅂ, ㄹ» всегда следует латинизировать как «g, d, b, l», а сопоставление остальных букв остается таким же, как указано в пункте 2. Заполнитель «ㅇ» в начале слога должен быть представлен знаком «-», но его следует опускать в начале слова. «-» следует использовать в других случаях, когда необходимо явно обозначить границу слога (устранить неоднозначность).0013
«-» следует использовать в других случаях, когда необходимо явно обозначить границу слога (устранить неоднозначность).0013
В ряде случаев эта латинизация может быть неоднозначной, потому что иногда несколько латинских букв сопоставляются одному объекту (jamo) в хангыле. Это происходит с гласными и согласными, последние немного сложнее, потому что есть как начальные, так и конечные согласные:
CLDR использует следующие правила для устранения неоднозначности возможных границ между буквами по порядку. Первое правило взято из пункта 8.
Если между гласными стоит один согласный, то Правило №1 сгруппирует его со следующим гласным, если он есть (это то же самое, что и первая часть пункта 8). Если между гласными имеется последовательность из четырех согласных, то возможен только один разрыв (при правильно построенном тексте). Таким образом, единственные неоднозначности связаны с двумя или тремя согласными между гласными, где возможны многосимвольные согласные.![]() Даже в этом случае в большинстве случаев решение простое, потому что нет возможного многознакового согласного в случае двух или двух возможных многознаковых согласных в случае 3. Например, в следующих случаях левая сторона однозначно:
Даже в этом случае в большинстве случаев решение простое, потому что нет возможного многознакового согласного в случае двух или двух возможных многознаковых согласных в случае 3. Например, в следующих случаях левая сторона однозначно:
ангда = анг-да → 앙다
апда = ап-да → 앞다
Существует относительно небольшое количество возможных двусмысленностей, перечисленных ниже с использованием «а» в качестве образца гласной.
Для последовательностей гласных ситуация проще. Применяется только Правило №3, поэтому aeo = ae-o → 애오.
Японский
Транслитерация по умолчанию для японского языка использует упрощенный вариант системы Хепберн. В системе Хепберна как ZI (ジ), так и DI (ヂ) представлены как «ji», а ZU (ズ) и DU (ヅ) представлены как «zu». Это немного изменено для обратимости за счет использования «dji» для DI и «dzu» для DU.
Транслитерация по умолчанию использует стандартную транскрипцию для греческого языка, которая направлена на сохранение этимологии.![]() Вариант ISO 843 включает следующие отличия:
Вариант ISO 843 включает следующие отличия:
* перед γ, κ, ξ, χ
Кириллица
Кириллица обычно следует ISO 9 для базового набора кириллицы. В будущем планируется добавить расширенные символы кириллицы, а также варианты для ГОСТ и других национальных стандартов.
Транслитерация индийских алфавитов соответствует стандарту ISO 159.19 Транслитерация деванагари и связанных с ним индийских шрифтов латинскими буквами . Внутри все индийские сценарии транслитерируются путем преобразования сначала во внутреннюю форму, называемую межиндийскими, а затем из межиндийских в целевой сценарий. Таким образом, Inter-Indic обеспечивает стержень между различными сценариями и содержит расширенный набор соответствий для всех из них.
ISO 15919 отличается от ISCII 91 применением диакритических знаков для некоторых символов. Эти различия показаны в следующем примере (проиллюстрирован деванагари, хотя те же принципы применимы и к другим индийским письмам):
Правила транслитерации с индийского языка на латиницу обратимы, за исключением ZWJ и ZWNJ, используемых для запроса явных эффектов рендеринга.![]() Например:
Например:
Транслитерация между индийскими сценариями выполняется туда и обратно, где есть соответствующие буквы. В противном случае могут быть откаты.
Есть два особых случая, когда транслитерация может привести к неожиданным результатам: (1) когда последняя гласная опущена в речи, и (2) при транслитерации «с».
Например:
Другие
Unicode CLDR предоставляет другие транслитерации, основанные на транслитерации Совета по географическим названиям США (BGN). В настоящее время они однонаправленные — только для латиницы. Цель состоит в том, чтобы сделать их двунаправленными в будущих версиях CLDR.
Другие транслитерации обычно основаны на транслитерации UNGEGN: Рабочая группа по системам латинизации. Эти системы в настоящее время реализованы шире, чем большинство стандартизированных транслитераций ISO, и опубликованы в свободном доступе в Интернете (http://www. eki.ee/wgrs/) и, таким образом, легко доступны для всех. UNGEGN также имеет хорошую документацию. Например, арабские таблицы UNGEGN не только представляют систему ООН, но и сравнивают ее с BGN/PCGN 19.56, I.G.N. Система 1973 г., ISO 233:1984, королевская система географического центра Иордании и система обзора Египта.
eki.ee/wgrs/) и, таким образом, легко доступны для всех. UNGEGN также имеет хорошую документацию. Например, арабские таблицы UNGEGN не только представляют систему ООН, но и сравнивают ее с BGN/PCGN 19.56, I.G.N. Система 1973 г., ISO 233:1984, королевская система географического центра Иордании и система обзора Египта.
Отправка транслитераций
Если вы заинтересованы в предоставлении транслитераций для одного или нескольких скриптов, отправьте первоначальный отчет об ошибке по адресу Locale Bugs . Первоначальная ошибка должна содержать задействованные скрипты и/или языки, используемую систему (со ссылкой на полное описание предлагаемой системы транслитерации) и краткий пример. Предлагаемые данные также могут быть в этой ошибке или добавлены в ответ на эту ошибку. Вы также можете сообщить об ошибке в Locale Bugs , если вы обнаружите проблему в существующей транслитерации.
Для отправки в CLDR данные должны быть предоставлены в правильном формате XML или в формате ICU и соответствовать принятому стандарту (например, UNGEGN, BGN или другим).
Формат правил указан в Transform_Rules. Лучше всего сначала протестировать результаты с помощью ICU Transform Demo , поскольку, если данные не пройдут проверку, они не будут приняты в CLDR.
Как упоминалось выше, даже если транслитерация используется только в определенных странах или контекстах, CLDR может предоставить для них различные теги вариантов.
Для сравнения можно посмотреть, что сейчас находится в CLDR в папке transforms онлайн. Например, см. иврит-латинский.xml.
Транслитераторы сценариев должны охватывать каждый символ в наборах образцов для локалей CLDR, использующих этот сценарий.
Латинизация (Script-Latin) должна охватывать все буквы ASCII (некоторые из них могут быть резервными сопоставлениями, например «x» ниже).
If the rules are very simple, they can be supplied in a spreadsheet, with two columns, such as
More Information
For more information, see:
BGN : Совет США по географическим названиям
UNGEGN: ГРУППА ЭКСПЕРТОВ ООН ПО ГЕОГРАФИЧЕСКИМ НАЗВАНИЯМ: Рабочая группа по системам латинизации
Транслитерация нелатинских алфавитов и письменностей (Томас Т.
 Педерсен)
Педерсен)Standards for Archival Description: Romanization
ISO-15915 (Hindi)
ISO-15915 (Gujarati)
ISO-15915 (Kannada)
ISCII-91
UTS #35: Язык наценки данных локали (LDML)
9 Правила арабской английской трансляции [Понимаете Коран]
от табассума Moslehs 10. 3 48444 40013
от табассума
بs власти
بs власти
.
.
.
.
.0013
Если вы откроете любую из стандартных исламских книг от хороших издателей, вы увидите, что они всегда используют стандартную систему транслитерации для тех терминов, которые не полностью сохранят свое значение при переводе на английский язык, и они также не могут быть написаны на английском языке. своего рода неформальный язык чата, который мы используем в таких каналах, как Facebook.
своего рода неформальный язык чата, который мы используем в таких каналах, как Facebook.
Вот несколько причин научиться использовать транслитерацию:
- Написание термина на языке чата может изменить произношение и, следовательно, значение слова. Например, ḍ alālah означает порча , тогда как dalalah означает руководство .
- Изучение транслитерации поможет нам легко понять ее, когда мы столкнемся с ней в книгах.
- Это сделает ваш текст более зрелым и научным, а значит, увеличит его вес.
- Это позволит вам получать более высокие оценки за задания.
- Мы должны научиться этому, если хотим, чтобы к нашей работе относились серьезно.
Итак, вот правила:
- Поместите строку поверх всех madd букв: ā, ī, ū.
- Используйте открывающую кавычку для ع, например. ‘айн (عين). Используйте закрывающий для всех типов hamzah , например: qara’a (قرأ), sā’il (سائل) (но вам не нужно использовать его, если он находится в начале, например, акала (أكل).
 ).
). - Для следующих пяти букв используйте точку внизу: ح ḥ,ص ṣ, ض ḍ, ط ṭ, ظẓ.
- Для не-madd ya и waw , используйте y и w соответственно, например наум (نوم), шейх (شيخ), далв (دلو)
- Используйте á для алиф максура, г. ḥ att á (حتى)
- Используйте t для ة только тогда, когда это mu ḍ āf , в противном случае используйте h . например sidrat al-muntah á .
- Для shaddah просто удвойте букву (например, shaddah ) или соответствующий диграф (например, kadhdhāb ). Исключение: وّ предшествует ḍ ammah , например. ‘ adūw (عدو), и يّ, которому предшествует kasrah , например. Ханафи (حنفيٌّ)
- Озвучивание конечной гласной или танвин:
- Для глаголов: озвучить окончание, за исключением случаев, когда слово стоит в самом конце предложения.
 (например, йалиджу аль-лайлах аль-нахар , хум юкинун )
(например, йалиджу аль-лайлах аль-нахар , хум юкинун ) - Для существительных: не озвучивать (например, qabr вместо qabrun ) Исключение: manqūṣ существительных, напр. wā d in, thānin, qā ḍ in, ma’nan
- Для наречий, предлогов, союзов, местоимений и указательных местоимений: озвучивать. (например, анна, байна, хадха, анта, лайлатан )
- Для глаголов: озвучить окончание, за исключением случаев, когда слово стоит в самом конце предложения.
- Дефисы:
- Используйте для соединения неразделимых предлогов и союзов: li-, wa-, fa-, bi- .
- Для определенного артикля al-. Никогда не присоединяйте al- к предыдущему слову (например, al-hurūf al-shamsīyah, , а не al-hurūful-shamsīyah ), ни изменить его, чтобы он соответствовал буквам солнца (например, . , а не ash-shamsīyah ).
- Для разделения проблемных комбинаций букв используйте символ штриха ′, который отличается от кавычек, например.

Leave a Reply